

R&D チームの徳田(@dakuton)です。
過去記事に引き続き、今回もテキスト抽出をさくっといい感じにしようシリーズです。
LayoutParserとは
物体検出を追加利用したドキュメント向けレイアウト解析ツールです。
各種OCRのロジックとして物体検出がすでに組み込まれているケースも多数ありますが、それとは別途、大まかなレイアウトに対する物体検出結果を合成し、意味のあるまとまりのテキストで補正抽出することが可能です。
オプションインストール(OCR向け)を含めた場合、LayoutParserのサポート範囲を図にすると以下のとおりです。
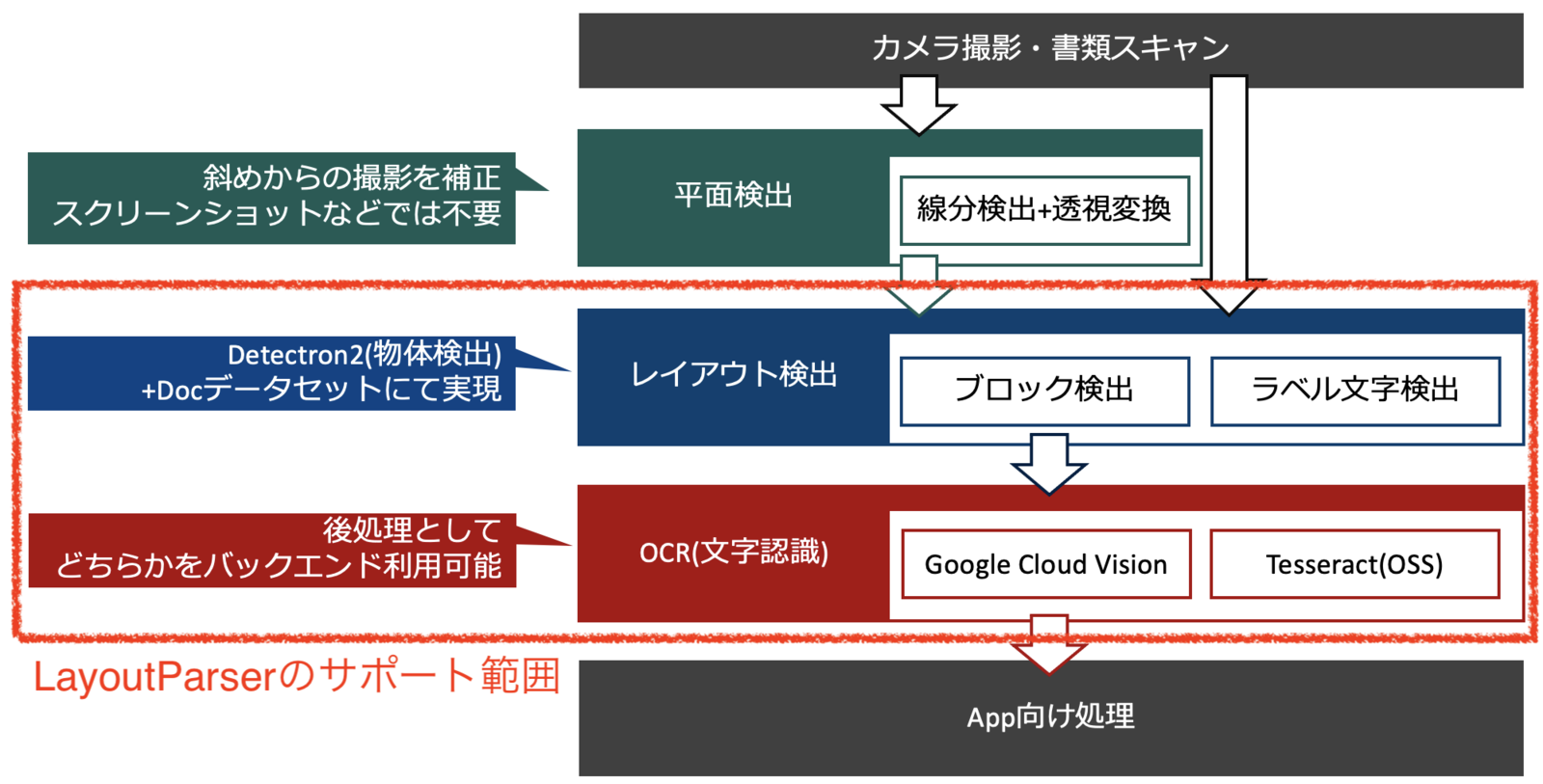
図の補足
- カメラ撮影など撮影方向が不定となる場合は、別途、平面補正処理が必要です。(LayoutParserのサポート外)
- 厳密にいえばLayoutParserにおいてレイアウト検出とOCRの実行順に依存関係はありません(OCR->レイアウト検出の順でも実行可)が、arXiv paperでの図を加味し本記事においても検出領域が大きい順に記載しています。
- 本記事の執筆時点(2021/08/03)では、OCRエンジンとしてGoogle Cloud Vision(ドキュメント テキスト検出)とTesseractの2種類をサポートしています。
テストデータ
今回は、夏季インターンシップ募集ページの部分スクリーンショット(コース概要)を使用しました。
事前準備(Google Cloud Visionの「ドキュメント テキスト検出」を利用する場合)
- Google Cloud Vision サービス アカウント キーの発行
- LayoutParser(installation)と
opencv-pythonのインストール(LayoutParserの依存関係に含まれていますが、今回サンプルコードで明示的に利用しているため個別に記載しておきます)
サンプルコード(parse_table_layout.py)
利用するレイアウト検出モデルを変更する場合は、Model Zooの記載に従い適宜変更してください。
import argparse import cv2 import layoutparser as lp def main(): args = parse_args() image = cv2.imread(args.src) detectron2_model = lp.Detectron2LayoutModel( 'lp://PubLayNet/mask_rcnn_X_101_32x8d_FPN_3x/config', extra_config=['MODEL.ROI_HEADS.SCORE_THRESH_TEST', 0.5], label_map={0: 'Text', 1: 'Title', 2: 'List', 3:'Table', 4:'Figure'} ) detectron2_layout = detectron2_model.detect(image) ocr_agent = lp.GCVAgent.with_credential(args.gcp_credential_json, languages=['ja']) res = ocr_agent.detect(image, return_response=True) ocr_layout = ocr_agent.gather_full_text_annotation(res, agg_level=lp.GCVFeatureType.BLOCK) print('### レイアウト解析なし') print('\n'.join(ocr_layout.get_texts()).replace(' ', '')) print('### レイアウト解析あり(図表エリアごとにテキスト抽出)') for l in detectron2_layout: if l.type in ['Table' ,'Figure']: texts = ocr_layout.filter_by(l.block, center=True).get_texts() print('\n'.join(texts).replace(' ', '')) def parse_args(): parser = argparse.ArgumentParser() parser.add_argument('--gcp_credential_json', type=str) parser.add_argument('--src', type=str) args = parser.parse_args() return args if __name__ == '__main__': main()
実行結果
前述のサンプル実行コマンド
$ python parse_table_layout.py --src intern_2021.png --gcp_credential /path/to/credential.json
のテキスト抽出結果は下記のようになります。
### レイアウト解析なし コース概要 COURSEOUTLINE R&D(研究開発) バックエンドエンジニア フロントエンドエンジニア AIの研究開発に携わっていただきます。 GPUを使った画像解析関連の機械学習に関するテーマに加えて、今年からは新たにエッジデバイスを用いた推論もテーマとして選択いただけます。詳細は募集要項をご覧ください。 バックエンド技術を用いて、新たな価値の創造や課題解決をしたい方向けの実務的なインターンシップです。AI・IoTプラットフォームや大規模BtoBサービスに関連する開発など、さまざまな内容を用意しています。 フロントエンド技術を用いて、新たな価値の創造や課題解決をしたい方向けの実務的なインターンシップです。画像解析サービスやデバイス可視化サービスのフロントエンド開発など、さまざまな内容を用意しています。 求める人材 求める人材 求める人材 機械学習・深層学習・画像解析いずれかの経験がある方、もしくは検討されている方 ご自身で何らかのシステム、アプリケーションの開発経験がある方 ご自身で何らかのシステム、アプリケーションの開発経験がある方 エントリー > エントリー > エントリー ### レイアウト解析あり(図表エリアごとにテキスト抽出) AIの研究開発に携わっていただきます。 GPUを使った画像解析関連の機械学習に関するテーマに加えて、今年からは新たにエッジデバイスを用いた推論もテーマとして選択いただけます。詳細は募集要項をご覧ください。 求める人材 機械学習・深層学習・画像解析いずれかの経験がある方、もしくは検討されている方 エントリー > バックエンドエンジニア バックエンド技術を用いて、新たな価値の創造や課題解決をしたい方向けの実務的なインターンシップです。AI・IoTプラットフォームや大規模BtoBサービスに関連する開発など、さまざまな内容を用意しています。 求める人材 ご自身で何らかのシステム、アプリケーションの開発経験がある方 エントリー > フロントエンドエンジニア フロントエンド技術を用いて、新たな価値の創造や課題解決をしたい方向けの実務的なインターンシップです。画像解析サービスやデバイス可視化サービスのフロントエンド開発など、さまざまな内容を用意しています。 求める人材 ご自身で何らかのシステム、アプリケーションの開発経験がある方 エントリー
フィルタ条件指定なしの場合は、左上からidが割り当てられ、idが小さい順にすべてのテキストが抽出されます。
サンプルデータだと一部テキストがテーブルエリア外にはなっています(テキストブロックの重心を記述とした場合、左テーブル先頭のR&D(研究開発)が検出漏れになっています)が、おおむねfilter_byで指定したレイアウトグループ範囲に含まれるテキストのみ抽出できています。
OCRとレイアウトそれぞれの検出位置を可視化した場合は下記のとおりです。
元画像

解析結果
- 赤枠: OCR(Google Cloud Vision ブロック検出)
- 青色透過: ドキュメントレイアウト(Detectron2)

LayoutParserを利用するメリット・デメリットは?
メリットと確実にいえる点はarXiv paperで述べられているとおり、OCR部分とレイアウト解析部分をモジュール分離することで再利用性が上がる点です。
また、既存の画像処理(エッジ検出など)によるレイアウト解析と比較して、LayoutParserで用意されているレイアウト解析モデルについては、罫線や塗りつぶしの存在しないテーブルなどレイアウト境界が明確でないドキュメントでもまとまった情報として抽出できる点がメリットとしてあげられるかもしれません。(examplesをみた仮説であり、追加検証が必要)
ただし、下記のような一般物体検出(ドキュメントレイアウト検出に限定されない)で発生する課題への対応が必要となります。
- 適切な検出しきい値決定が必要になる(既存の画像処理で必要だったしきい値の代替パラメータ)
- 同じ座標に複数のレイアウト候補が検出された場合、NMS等による重複除去・集約が必要になる
罫線や塗りつぶしなど、図表とそれ以外のレイアウト境界が比較的はっきりしている場合は、既存の画像処理で対応したほうが確実かもしれません。
- 参考記事: ExcaliburによるPDFテーブルデータ抽出を動かしてみるの「検出ロジック解説」
おわりに
あらためて、今回用いたデータはこちらです。(2021年度の募集は締め切りました。多数応募いただきありがとうございます。) www.optim.co.jp
また、オプティムでは技術をいい感じに使ってデジタライゼーションに貢献できるエンジニアを募集しています。