R&Dチーム所属の伊藤です。気がついたら半年ぶりくらいの投稿になってしまいました。
今回はrinna株式会社より公開された言語画像モデルである日本語対応CLIPを使ってみた話になります。 元々はCLIPとFaissを組み合わせて画像検索のためのツールを作れないかを試していたのですが、どうせだったら可視化までしようと考えてStreamlitを使用したアプリ化も行いました。 今回作成したコードはGithubのリポジトリにありますので、興味がある方は覗いてみてください。
CLIPとは?
CLIPはOpenAIより提案された、テキストと画像を使用して画像分類モデルです。 CLIPはContrastive Language–Image Pre-training(対照的言語画像事前学習)の略であるため厳密には学習手法のことを指しているのですが、今回はその手法で学習したモデルをCLIPと呼ぶことにします。
CLIPは画像と、その画像の説明となるテキストのペアから学習を行います。 具体的には、画像のベクトル(もしくは埋め込み表現)を取得するための画像エンコーダとテキストのベクトルを取得するテキストエンコーダを用意して、画像とテキストのベクトルが近くなるようにモデルを学習させます。 これらの埋め込みを比較することにより、画像分類を行うのがCLIPの特徴です。 例えばある画像が猫か犬かを判別する時は、画像エンコーダに画像を入力として得られたベクトルと、テキストエンコーダに「犬」と「猫」を入力として得られたベクトルをそれぞれ比較し、もし「犬」のベクトルが画像のベクトルより近いならば犬と、そうでないならば猫といったように分類を行うことができます。
そんなCLIPですが、rinna株式会社より日本語に特化したモデルが公開されています(プレスリリース)。 公開されているモデルはPythonのHuggingFaceライブラリから使用することが可能であり、簡単に試すことができます。
このモデルを使って今回は画像検索を行なっていきます。 画像検索の仕組み自体は単純で、あるテキストを検索クエリとした時にテキストエンコーダから得られるベクトルに対して、いくつかの画像エンコーダから得られるベクトルのうち最も近いベクトルを選びます。 前述の通り、CLIPは画像とその画像の説明となるテキストのベクトルが近くなるように学習を行なっているため、ここで得られる画像が検索に使用したテキストに最も近いものとなるはずです。
Faissとは?
FaissはMetaAIによって開発されたベクトルの類似検索・クラスタリングのためのライブラリです。 C++で開発されていますがPythonのラッパーが存在し、高速に動作することが特徴の1つとなっています(GPUを使用しての実行も可能です)。
今回はこのFaissを使って、CLIPで得られたベクトルの検索を行うことにします。 もちろん、自前でベクトル同士の距離を比較するコードを書いてもよかったのですが、前々からこのライブラリを使ってみたいと考えていたため今回はFiassを採用しています。
CLIPとFaissで画像検索
さて、それではCLIPとFaissで画像検索を試してみます。 対象となる画像として、今回はThe Oxford-IIIT Pet Datasetという37種の犬と猫の画像からなるデータセットを使っていきます。 The Oxford-IIIT Pet DatasetはCC BY 4.0で公開されています。

本データセットには7390枚の画像が含まれていますが、今回はその中の310枚のみを使用して検索対象としました。
事前準備
今回はPython3.9系を使用してプログラムを書いています。
まずはCLIPを使うためのライブラリのインストールを行います。日本語CLIPのチュートリアルを参考に行えば問題ありません。
$ pip install git+https://github.com/rinnakk/japanese-clip.git
次にFaissです。インストールの方法はいくつか存在しますが、公式のINSTALL.mdにあるcondaを使用した方法が最も簡単だと思います。
$ conda install -c conda-forge faiss-cpu
今回はCPU版を使用しています。
画像ベクトルのインデックス作成
Faissではベクトルを検索対象に含めたインデックスを作成する必要があります。 今回の検索対象は画像ベクトルとなるので、画像をエンコーダに通したベクトルを登録します。
まずは、検索対象となる画像のベクトルを求めます。
ある引数のディレクトリパスにあるjpegファイルを画像ベクトルに変換し、画像ファイルとベクトルのリストを返すcreate_dataset()という関数を作成しました。
CLIPモデルのインスタンスは他でも使用するため、モデルのロードのためのload_models()関数も用意しています。
import glob import itertools import os from PIL import Image import torch import japanese_clip as ja_clip def load_models(): clip, preprocess = ja_clip.load( "rinna/japanese-clip-vit-b-16", cache_dir="/tmp/japanese_clip") tokenizer = ja_clip.load_tokenizer() return { 'clip': clip, 'preprocess': preprocess, 'tokenizer': tokenizer, } def create_dataset(dataset_dir, models, batchsize=50): image_path_list = glob.glob(os.path.join(dataset_dir, '*.jpg')) vector_list = [] idx = 0 while True: image_path_batch = list(itertools.islice(image_path_list, idx, idx + batchsize)) if len(image_path_batch) == 0: break print('Get vectors from image {} to {}...'.format(idx, idx + batchsize)) idx += batchsize images = [Image.open(image_path) for image_path in image_path_batch] processed = torch.cat([models['preprocess'](img).unsqueeze(0) for img in images], dim=0) with torch.no_grad(): vector_list.append(models['clip'].get_image_features(processed)) image_path_list = [f'{pl}\n' for pl in image_path_list] vectors = torch.cat(vector_list, dim=0) return { 'path_list': image_path_list, 'vectors': vectors.detach().numpy(), }
次に、得られたベクトルからインデックスを生成します。
Faissで生成できるインデックスには種類があるのですが、今回はFiass WikiのThis is too slow, how can I make it faster?を参考にしてIndexIVFFlatを採用しました。
Faissで使える典型的なインデックス(IndexFlatL2など)は、検索の際に全てのベクトルを対象とする(総当たり)ためかなりの時間がかかります。
IndexIVFFlatでは検索領域を事前にクラスタリングしておき、入力ベクトルと同じクラスタ付近の領域にあるベクトルのみと比較を行うことで時間の短縮を行なっています。
datasetsディレクトリに画像のデータを格納してこのスクリプトを実行することでoutput/image_list.txtに画像のパスのリストが、output/index.faissにインデックスが保存されます。
import faiss def create_clip_index(vectors, out_path, nlist=5): dim = 512 # vector dimension by CLIP quantizer = faiss.IndexFlatL2(dim) index = faiss.IndexIVFFlat(quantizer, dim, nlist) index.train(vectors) # clustering index.add(vectors) faiss.write_index(index, out_path) def main(): dataset_dir = 'datasets' out_dir = 'output' image_list_path = os.path.join(out_dir, 'image_list.txt') index_path = os.path.join(out_dir, 'index.faiss') os.makedirs(out_dir, exist_ok=True) models = load_models() dataset = create_dataset(dataset_dir, models) image_list = dataset['path_list'] vectors = dataset['vectors'] with open(image_list_path, 'w') as f: f.writelines(image_list) create_clip_index(vectors, index_path) if __name__ == '__main__': main()
インデックスを読み込んで画像検索
次に、先ほど保存したインデックスを読み込んで、実際にテキストから画像の検索を行なってみます。 新しく下記のスクリプトを準備しました。
search()関数が検索を行うための関数であり、テキストをCLIPのテキストエンコーダに入力して得られたテキストベクトルをクエリとして、保存したインデックスからクエリに近いベクトルをk個探します。
import torch import faiss import japanese_clip as ja_clip def load_models(): clip, preprocess = ja_clip.load( "rinna/japanese-clip-vit-b-16", cache_dir="/tmp/japanese_clip") tokenizer = ja_clip.load_tokenizer() return { 'clip': clip, 'preprocess': preprocess, 'tokenizer': tokenizer, } def text2vectors(texts, models): encodings = ja_clip.tokenize( texts=texts, tokenizer=models['tokenizer'], ) with torch.no_grad(): vectors = models['clip'].get_text_features(**encodings) return vectors.detach().numpy() def load_image_list(image_list_path): with open(image_list_path) as f: lines = f.readlines() return [line.strip() for line in lines] def load_index(index_path): index = faiss.read_index(index_path, faiss.IO_FLAG_MMAP) return index def search(query, index, k=3): _, searched_index = index.search(query, k) return searched_index def main(): models = load_models() image_list = load_image_list('output/image_list.txt') index = load_index('output/index.faiss') texts = ['黒い犬'] query = text2vectors(texts, models) result = search(query, index) for img_idx in result[0]: print(image_list[img_idx]) if __name__ == '__main__': main()
このスクリプトを実行すると、次の結果が得られました。
datasets/newfoundland_1.jpg datasets/newfoundland_6.jpg datasets/newfoundland_7.jpg
これらの画像が検索テキストである「黒い犬」に最も近い3枚ということになります。 以下の通り、実際に黒い犬の画像が選ばれていることが確認できます。



Streamlitで画像検索アプリを作成する
せっかくCLIP+Faissによる画像検索が実現できたので、次はこれをWebアプリとして実行できるようにします。 今回は、Pythonのみで簡単にWebアプリが作成できるフレームワークであるStreamlitを使用してアプリを作成しました。
Streamlitのインストールはpipで行えます。
$ pip install streamlit
先ほど定義した関数を使って画像検索を行うスクリプトをmain.pyとして準備します。
import time import streamlit as st from PIL import Image def main(): st.set_page_config(layout="wide") with st.spinner('Loading...'): models = load_models() image_list = load_image_list('output/image_list.txt') index = load_index('output/index.faiss') st.title('Image search by Japanese-CLIP') col1, col2, col3, col4 = st.columns(4) with col1: with st.form('text_form'): search_text = st.text_input('Search Text', '黒い犬') button = st.form_submit_button('Search Image') if not button or search_text == '': st.stop() t2v_start = time.time() query = text2vectors([search_text], models) search_start = time.time() searched_index = search(query, index)[0] search_end = time.time() results = [image_list[idx] for idx in searched_index] st.write('Text to Vector: {:.4f}[s]'.format(search_start - t2v_start)) st.write('Search : {:.4f}[s]'.format(search_end - search_start)) cols = [col2, col3, col4] for i, img_path in enumerate(results): with cols[i]: img = Image.open(img_path) st.image(img, caption=img_path, use_column_width='always') if __name__ == '__main__': main()
このスクリプトを以下のように実行することで、デフォルトでは8501ポートでアクセス可能なWebサービスが起動します。
streamlit run main.py
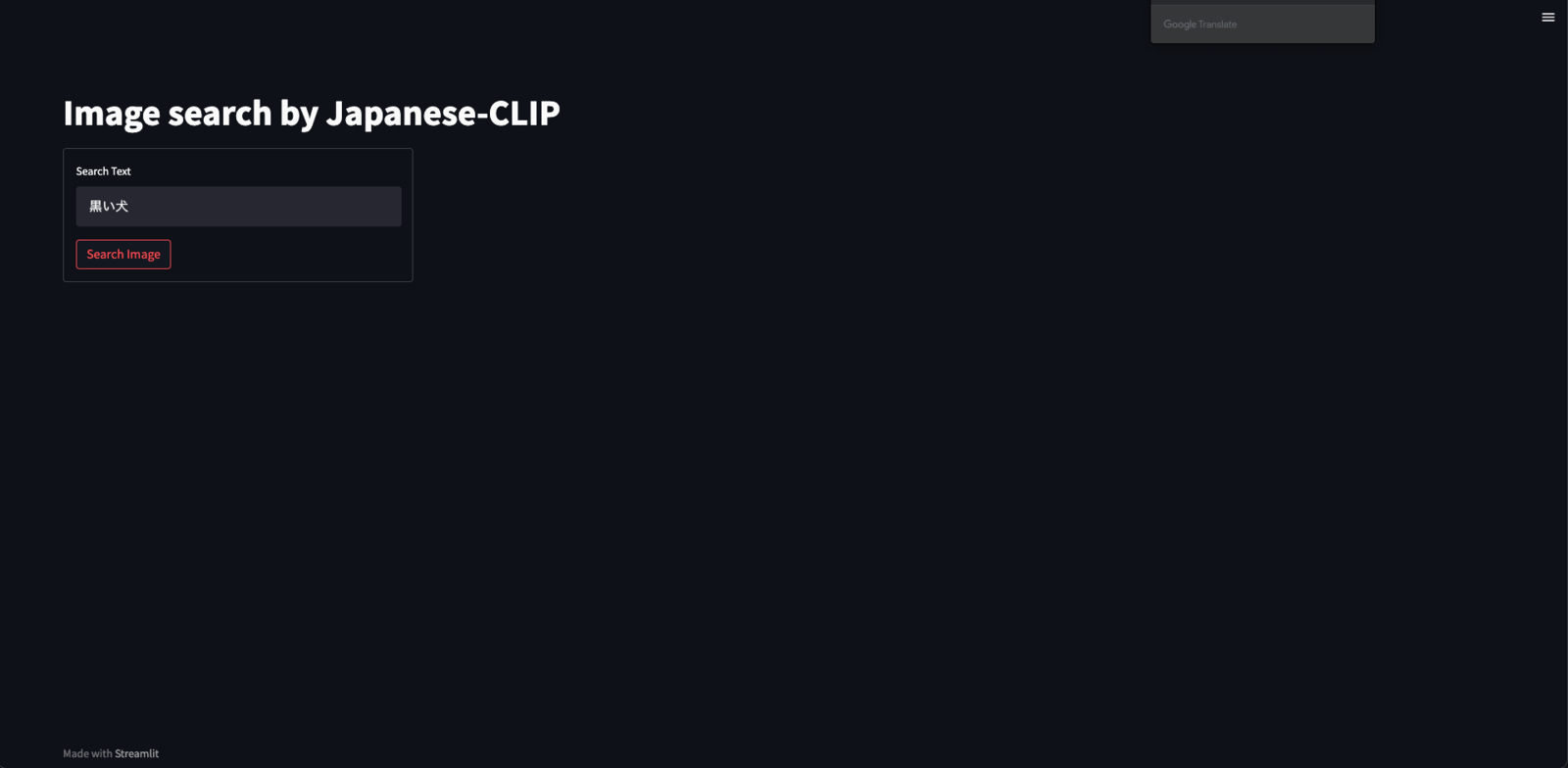
何かしらのテキストを入力してSearch Imageボタンをクリックすると、入力テキストを表すベクトルに近い画像ベクトルを持つ3つの画像が表示されます。

newfoundland_1, newfoundland_6, newfoundland_7@The Oxford-IIIT Pet Dataset/CC BY 4.0
検索テキストを「黒い犬」とした時に、先ほどの検索結果と同じ画像が表示されました!
もちろん別のテキストでも検索できます。 検索テキストを「白い犬」とした場合は以下のような結果になります。

great_pyrenees_6, wheaten_terrier_4, great_pyrenees_3@The Oxford-IIIT Pet Dataset/CC BY 4.0
最後に
CLIP+Fiass+Streamlitで画像検索アプリを作成しました。
この方法で画像検索を実装することの良い点は、検索対象となる画像にタグ付けが必要なくなるということです。 画像をCLIPでベクトル変換してインデックスに追加するだけでいいため、検索データが膨大になればなるほど役に立ちそうです。
また、アプリの検索結果画面の左下に表示されていますが、Faissの検索速度はかなり高速でした。 入力テキストをCLIPでベクトルに変換するのに0.1~0.3秒程度かかってしまいますが、そこからインデックスの検索にかかる時間はたったの1~2ミリ秒となっています。 CLIP、Fiass共にGPUを使用した高速化も可能なので、大規模な画像データに対しての検索手法として一考の余地はあると思います。
今回作成したコードはDockerで起動できるようにGithubのリポジトリにまとめてありますので、興味がある方は覗いてみてください。
オプティムでは埋め込みベクトルが好きなエンジニアを募集しています。