

はじめまして。R&Dチーム所属、20.5卒の伊藤です。
普段の業務では自然言語処理と格闘していることが多いです。
今回は自然言語処理モデルとして有名なBERTをWebAssemblyを使用してフロントエンドで動かしてみた話になります。
最近、自然言語処理ライブラリとして普段お世話になっているHugging Face社のTransformersのTokenizerがRustで実装されていることを知り、それならばWebAssemblyにコンパイルして動かせるのではないかと試したみたのがきっかけです。
Tokenizerのみ動かしても実用性に乏しいため、Tokenizerから得られた結果からBERTを用いた推論をブラウザで動作させるまでを行い、備忘録がでら手順をまとめました。
どなたかの参考になれば幸いです。
8/26追記
本記事内のコードを含むリポジトリを公開しました!Dockerを使用してブラウザでの動作を確認できるようになっています。
BERTモデルの準備
まずは、BERTモデルをダウンロードし、後々Rustで実行するためにONNX形式に変換します。 扱いたいTokenizerの関係上、今回はHuggingFace Model Hubにある事前学習済みBERTモデルの1つ、bert-base-casedを使用します。
モデルのダウンロード、及びONNX形式の変換はTransformersライブラリにスクリプトが付属しているため、pythonが使える環境であるならば簡単に実行が可能です。
pip install transformers # Transformersがインストールされた場所を確認 pip show transformers # /path/to/transformers/はTransformersライブラリがインストールされている場所 python /path/to/transformers/convert_graph_to_onnx.py --pipeline fill-mask --model bert-base-cased --framework pt bert-masked.onnx
上記のコマンドを実行すると、カレントディレクトリ にbert-mased.onnxというONNX形式のモデルが生成されます。
その他の引数についての説明は以下の通りです。
--pipeline {feature-extraction,ner,sentiment-analysis,fill-mask,question-answering,text-generation,translation_en_to_fr,translation_en_to_de,translation_en_to_ro}
--model MODEL Model's id or path (ex: bert-base-cased)
--tokenizer TOKENIZER
Tokenizer's id or path (ex: bert-base-cased)
--framework {pt,tf} Framework for loading the model
--opset OPSET ONNX opset to use
--check-loading Check ONNX is able to load the model
--use-external-format
Allow exporting model >= than 2Gb
--quantize Quantize the neural network to be run with int8
今回はpiplineとしてfill-maskを指定しました。
これを指定すると、BERTをMasked Language Modelとして使用するモデルを生成します。
Masked Language Model (MaskedLM)はマスクされている単語を含む文を入力とし、その単語を予測するモデルです。
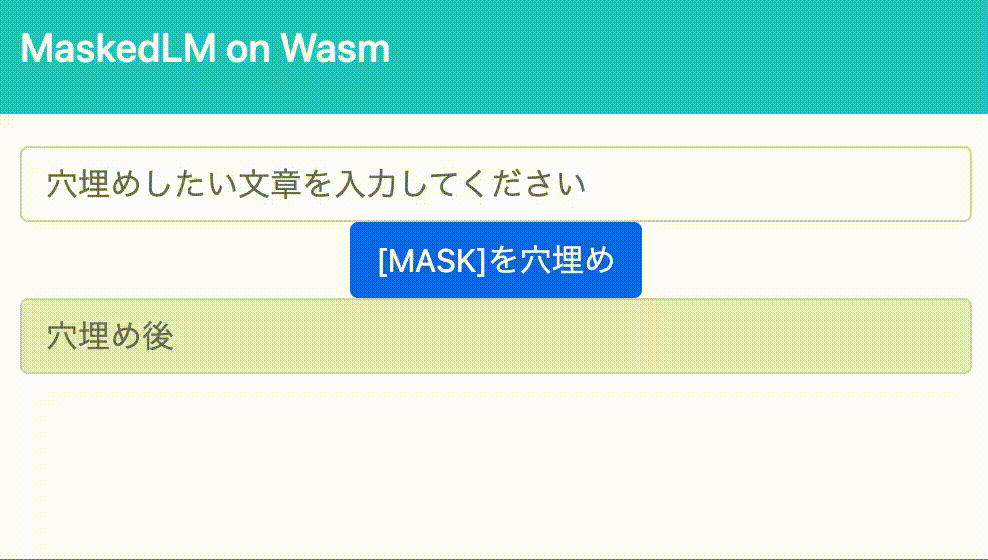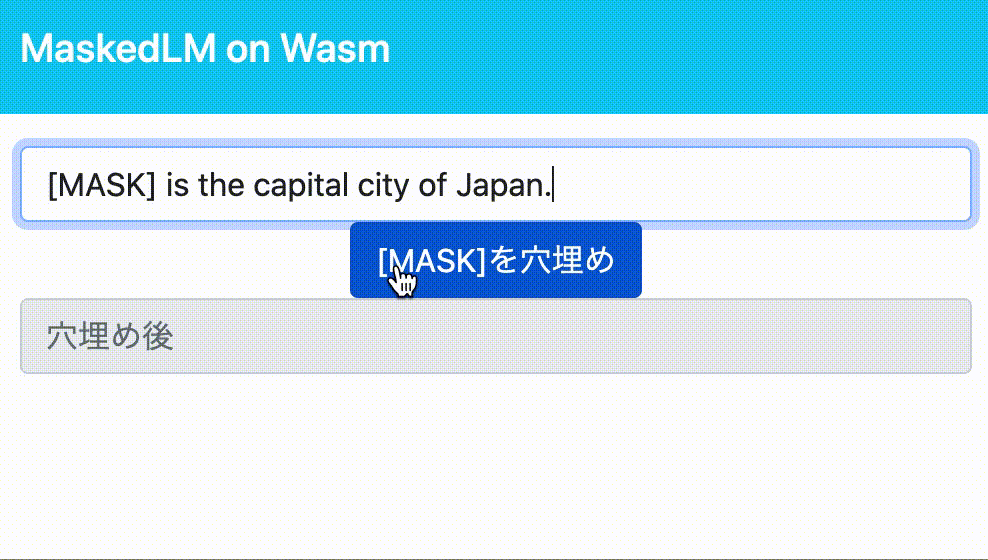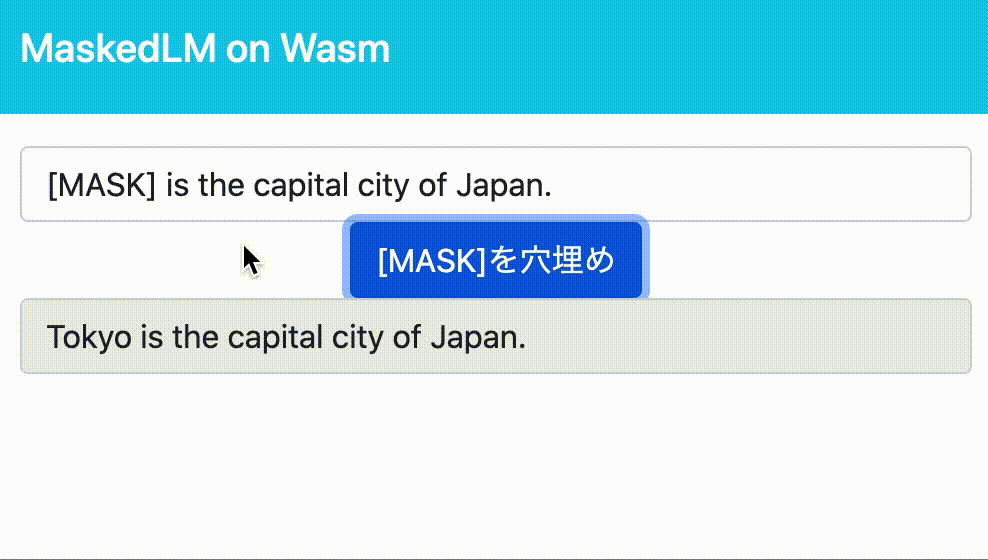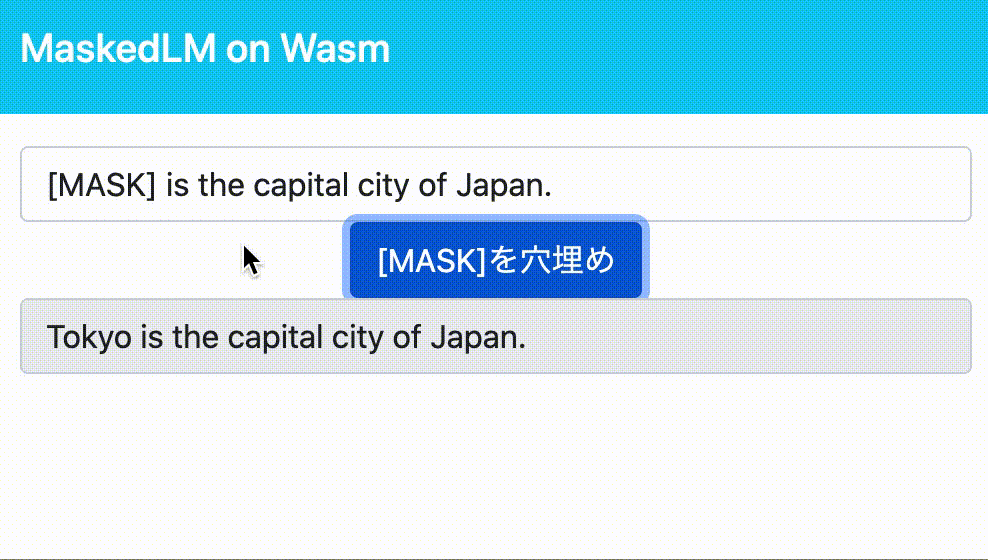
例として、[MASK] is the capital city of Japan.という文が入力された場合、モデルは[MASK]の中に入る単語とその確率を予測します。
ちなみに、今回用いるBERTモデルはTokyoを最も入る確率の高い単語として予測します。
このMaskedLMはBERTの事前学習で既に訓練されているタスクであるため、事前学習モデルをそのまま使うことが可能です。
piplineの他の候補である翻訳モデル(translation_en_to_fr)等はモデルの追加学習が必要となるため、今回はMaskedLMを使用することにしました。
RustでBERTの推論を行うWebAssemblyの生成
プロジェクト構成
プロジェクト管理ツールとしてCargoが入っていることを前提とします。 以下のコマンドでライブラリ用プロジェクトを作成します。
cargo new --lib maskedlm cd maskedlm
次に、生成したONNX形式のBERTモデルとTokenizerに使用するvocabファイル(token->idのマッピングを示すテキストファイル)をプロジェクトに追加します。
mv /path/to/bert-masked.onnx . curl -O https://huggingface.co/bert-base-cased/raw/main/vocab.txt
また、Wasmへのコンパイルのため、wasm-packをインストールします。
cargo install wasm-pack
作成したプロジェクト直下のCargo.tomlの[dependencies]以下を次のように変更します。
[dependencies] tokenizers = "0.10.1" tract-onnx = "0.15.2" wasm-bindgen = "0.2.74" [lib] crate-type = ["cdylib"]
使用するクレートについての詳細は以下のとおりです。
- tokenizers : HuggingFace社製のTokenizer
- tract-oonx : ONNX形式のニューラルネット推論のツールキット
- wasm-bindgen : WebAssemblyとJavaScript連携のためのラッパー
以下のパスをsrc/lib.rs内のスコープに追加します。
また、ここから下のRustコードは全てsrc/lib.rsに追加されてるものとしてお読みください。
use std::collections::HashMap; use std::io::BufReader; use tokenizers::tokenizer::{Result, Tokenizer, EncodeInput, Encoding, AddedToken}; use tokenizers::*; use tract_onnx::prelude::*; use tract_onnx::prelude::tract_ndarray::*; use wasm_bindgen::prelude::*;
Tokenizerの作成
tokenizersクレートには、BERT向けのTokenizer設定がデフォルトで用意されているのでそれを使用します。
fn create_tokenizer() -> Result<Tokenizer> { // Normalizer let normalizer = normalizers::bert::BertNormalizer::new(true, false, false, false); // PreTokenizer let pre_tokenizer = pre_tokenizers::bert::BertPreTokenizer; // Model let vocab_str = include_str!("../vocab.txt"); // Wasmに含めるため文字列としてファイルの中身を置き換える let mut vocab = HashMap::new(); for (index, line) in vocab_str.lines().enumerate() { vocab.insert(line.trim_end().to_owned(), index as u32); } let wordpiece_builder = models::wordpiece::WordPiece::builder(); let wordpiece = wordpiece_builder .vocab(vocab) .unk_token("[UNK]".into()) .build().unwrap(); // Post processor let post_processor = processors::bert::BertProcessing::new(("[SEP]".into(), 102), ("[CLS]".into(), 101)); // Tokenizerの作成 let mut tokenizer = Tokenizer::new(Box::new(wordpiece)); tokenizer.with_normalizer(Box::new(normalizer)); tokenizer.with_pre_tokenizer(Box::new(pre_tokenizer)); tokenizer.with_post_processor(Box::new(post_processor)); // [MASK]トークンの追加 let mask_token = AddedToken::from("[MASK]".into()).single_word(true); tokenizer.add_special_tokens(&[mask_token]); Ok(tokenizer) }
この作成されたtokenizerは
// wordはTokenizeしたい文字列 let encoding: Encoding = tokenizer.encode(EncodeInput::Single(word.into()), true)?;
としてTokenizeに使用できます。
得られるEncoding型はTokenizerの出力で、以下のように定義されています。
BERTモデルへの入力テンソルを作成
Tokenizeの結果からBERTの入力データを作成します。 入力データに何が必要かについては、生成したONNXファイルをnetron等で読み込めば確認できます。
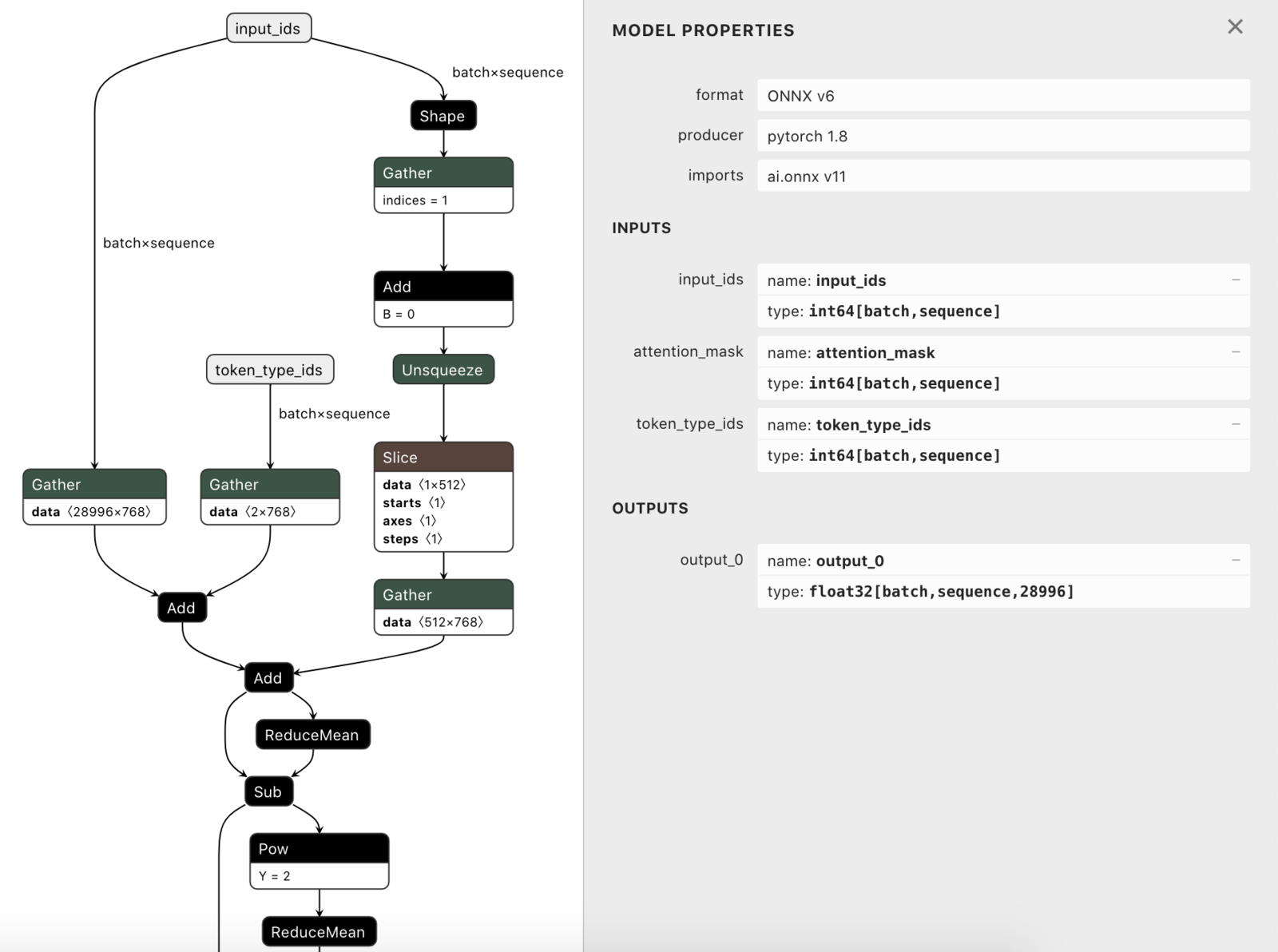
今回のBERTに必要なのは、input_ids,attention_mask,type_idsであるため、これらをtract_onnxでのモデル推論に対応したTVec型にまとめます。
fn create_input_tensor(encoding: &Encoding) -> Result<TVec<Tensor>> { // &[u32]->Tensorへの変換 fn element2tensor(element: &[u32]) -> Result<Tensor> { let e_i64: Vec<i64> = element.into_iter().map(|&e| e as i64).collect(); Ok(tract_ndarray::Array::from_shape_vec((1, e_i64.len()), e_i64)?.into()) } let ids: Tensor = element2tensor(encoding.get_ids())?; let attention_mask: Tensor = element2tensor(encoding.get_attention_mask())?; let type_ids: Tensor = element2tensor(encoding.get_type_ids())?; let input_tensor = tvec![ids, attention_mask, type_ids]; Ok(input_tensor) }
BERTによる推論
tract_onnxクレートを使用してONNX形式のモデルを読み込み、create_input_tensorによって生成された入力から推論を行います。
入力となるベクトルの大きさはモデルのロードの際に固定する必要があるため、入力トークンの長さseq_lengthも引数として渡しています。
モデルを動かすにあたってtract_onnxについての情報はほとんど見当たらなかったため、公式のexampleを参考にしました。
fn inference(input_tensor: TVec<Tensor>, seq_length: usize) -> Result<Array<f32, Dim<[usize; 2]>>> { // モデルのロード let onnx_model = include_bytes!("../bert-masked.onnx"); // Wasmに含めるためコンパイル時にファイルの中身を置換 let model = tract_onnx::onnx() .model_for_read(&mut BufReader::new(&onnx_model[..]))? .with_input_fact(0, InferenceFact::dt_shape(i64::datum_type(), tvec!(1, seq_length)))? .with_input_fact(1, InferenceFact::dt_shape(i64::datum_type(), tvec!(1, seq_length)))? .with_input_fact(2, InferenceFact::dt_shape(i64::datum_type(), tvec!(1, seq_length)))? .into_optimized()? .into_runnable()?; // 推論 let output = model.run(input_tensor)?[0] // 出力は1つなので[0]で取得 .to_array_view::<f32>()? .slice(s![0, .., ..]) // (1, seq_length, vocab_size) -> (seq_length, vocab_size) .into_owned(); Ok(output) }
推論結果のデコード
最後に推論結果から、[MASK]トークンに入る単語を求めます。
// [MASK]があるトークンの位置を求める fn get_mask_position(encoding: &Encoding) -> Vec<usize> { let mut mask_positions = Vec::new(); for (i, token) in encoding.get_tokens().into_iter().enumerate() { if token == "[MASK]" { mask_positions.push(i); } } mask_positions } // 配列から最も値の大きいインデックスを求める fn argmax<T: PartialOrd>(v: &[T]) -> usize { if v.len() == 1 { 0 } else { let mut maxval = &v[0]; let mut max_idx: usize = 0; for (i, x) in v.iter().enumerate().skip(1) { if x > maxval { maxval = x; max_idx = i; } } max_idx } } fn decode(output: &Array<f32, Dim<[usize; 2]>>, tokenizer: &Tokenizer, mask_positions: Vec<usize>, word: &str) -> Result<String> { let mut decoded: String = word.into(); for i in mask_positions { // 出力の最も大きいidを求める let prediction = output.slice(s![i, ..]); let prediction = prediction.as_slice().ok_or("Output is invalid")?; let max_id: u32 = argmax(prediction) as u32; // tokenizerによるデコード let word = tokenizer.decode(vec![max_id], false)?; // [MASK]の置換 decoded = decoded.replacen("[MASK]", &word[..], 1); } Ok(decoded) }
WebAssemblyへのコンパイル
最後に、これまでの関数をまとめます。
パブリック関数に#[wasm_bindgen]でバインディングすることで、JavaScriptから呼び出すことが可能になります。
#[wasm_bindgen] pub fn predict_masked_words(word: &str) -> String { run_predict(word).unwrap() } fn run_predict(word: &str) -> Result<String> { let tokenizer = create_tokenizer()?; let encoding = tokenizer.encode(EncodeInput::Single(word.into()), true)?; let mask_positions = get_mask_position(&encoding); let output = inference( create_input_tensor(&encoding)?, encoding.get_ids().len() )?; decode(&output, &tokenizer, mask_positions, word) }
このプロジェクトをwasm-pack buildでコンパイルすると、pkgディレクトリ下にwasmファイルとそのラッパースクリプト等が生成されます。
pkg ├── maskedlm.d.ts ├── maskedlm.js ├── maskedlm_bg.js ├── maskedlm_bg.wasm ├── maskedlm_bg.wasm.d.ts └── package.json
これでBERTで推論を行うためのWasmをコンパイルすることができました。
コンパイルしたWasmをフロントエンドで動かす
typescript+webpackを使用して先ほどコンパイルしたWasmを動かすプロジェクトを作成します。
パッケージ管理ツールとしてnpmコマンドが実行できる環境を前提にします。
先に作成したmaskedlmプロジェクトも含め、以下のディクトリ構成を持つプロジェクトを作成します。
. ├── maskedlm │ ├── Cargo.toml │ ├── bert-masked.onnx │ ├── pkg │ │ ├── maskedlm.d.ts │ │ ├── maskedlm.js │ │ ├── maskedlm_bg.js │ │ ├── maskedlm_bg.wasm │ │ ├── maskedlm_bg.wasm.d.ts │ │ └── package.json │ ├── src │ │ └── lib.rs │ └── vocab.txt ├── package.json ├── src │ ├── index.html │ └── index.ts ├── tsconfig.json └── webpack.config.js
まずは必要なパッケージをインストールします。
# package.jsonの生成 npm init -y # typescript npm install -D ts-loader tslint # webpack npm install -D webpack webpack-cli html-webpack-plugin # コンパイルしたWasmをwebpackから扱うためのプラグイン npm install -D @wasm-tool/wasm-pack-plugin # 開発用サーバー npm install -D webpack-dev-server
tsconfig.jsonを作成します。
{ "compilerOptions": { "target": "es2018", "module": "esNext", "strict": true, "strictNullChecks": true, "moduleResolution": "node", "noEmit": true, "esModuleInterop": true, } }
webpack.config.jsを作成します。wasm-pack-pluginを使用することで、webpackでのビルド時にwasm-packのビルドを走らせることができます。 また、wasm-bindgenによって生成されたコード内で.wasmファイルをrequireしているため、extensionsに.wasmを追加する必要があります。
const path = require("path"); const HtmlWebpackPlugin = require("html-webpack-plugin"); const WasmPackPlugin = require("@wasm-tool/wasm-pack-plugin"); module.exports = { resolve: { extensions: [".ts", ".tsx", ".js", ".jsx", ".wasm"] }, mode: "development", module: { rules: [ { test: /\.tsx?$/, loader: "ts-loader", options: { transpileOnly: true } } ] }, plugins: [ new HtmlWebpackPlugin({ template: path.join(__dirname, "src/index.html") }), new WasmPackPlugin({ crateDirectory: path.join(__dirname, "maskedlm") // RustプロジェクトのCargo.tomlがあるディレクトリを指定 }) ], experiments: { asyncWebAssembly: true, // wasm-bindgenで生成されたコードは全て動的モジュールとして扱う必要があるため }, };
src/index.htmlを作成します。今回は最低限の記述しかしていません。
<!DOCTYPE html> <html> <head> <meta charset="utf-8" /> <title>wasm-maskedlm</title> </head> <body> </body> </html>
最後に、エントリポイントとなるsrc/index.tsを作成します。
ここで、先程Wasmコンパイルしたファイルを含むmaskedlm/pkgディレクトリ をモジュールとして読み込むことで、Rustで定義した関数を呼び出すことができるようになります。
今回は[MASK] is the cpital city of Japan.という文を入力として[MASK]トークンの穴埋めをさせてみます。
import * as maskedlm from "../maskedlm/pkg"; // Wasmをモジュールとして読み込み const output = maskedlm.predict_masked_words("[MASK] is the capital city of Japan."); // BERTでの推論実行 console.log(output)
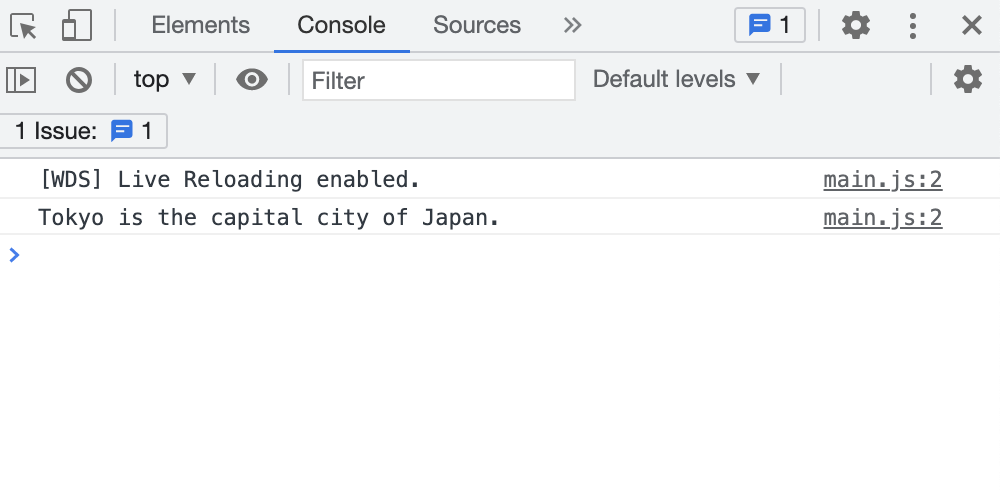
この状態でnpx webpack serveを実行することで、localhost:8080にサーバが立ち上がります。
ブラウザからコンソールを確認することで、推論結果であるTokyo is the capital city of Japan.が表示されていることが確認できます。
最後に
BERTを使用した推論パイプラインをWebAssemblyでコンパイルして、フロントエンドで動かすまでを試してみました。 今回フロントエンド部分のコードは最小限にしたため、決められた入力から単純に推論結果を表示するだけでしたが、もちろんインタラクティブに推論を行うことも可能です。
8/26追記
上記デモを実行するためのコードを公開しました。
オプティムでは自然言語処理に興味のあるエンジニアを募集しています。