

C++ Advent Calender 2024
この記事はC++ - Qiita Advent Calendar 2024 - Qiita の19日目の記事です。
- 18日目: C++ glaze JSONライブラリの紹介と条件-値フィルタリング #艦これ - Qiita by @kc-hedgehog
- 20日目: poacの現況 + 改造して遊んでみた by @I(wx257osn2)
はじめに
Optimal Biz PE-WebWin2チームのyumetodoです。
Optimal BizはMDMというカテゴリに位置づけられる製品です。WindowsのMDMを行うために、一般的なWindows Serviceアプリケーションとして開発されたWindows Agentが制御を行っています。
Optimal Biz Teleworkは、テレワークや在宅勤務における業務管理、モチベーション、体調管理、生産性向上をAIで支援するという製品です。
今年4月に誕生したPE-WebWin2チームはC++開発者を増やすべく作られたチームで、このWindows AgentとRuby on Railsを用いたサーバーサイドの開発の両方を行います。
そんな私達が最初に取り組んだ要件が、Optimal Biz Teleworkの機能のうち、「アプリケーションログ収集機能」をOptimal Bizに取り込みするというものでした。
この直前にVS2015化対応を行った私は、まさかそれを超える高難易度要件にぶつかるとは思っても見ないのでした。
COM STAの再入とはなにか
COMとはComponent Object Modelの略です。その詳細については上記の記事で解説しているので割愛します。
STA(Single Thread Apartment)において、別のアパートメント(例えば別のスレッドとか別のプロセスとか)のCOMオブジェクトのメソッド呼び出しはウィンドウメッセージによって達成されます。
上記ブログにはその詳細が解説されていますが、別のアパートメントのメソッドを呼び出すための手続きを書いてみるとこうなります。

- メソッド呼び出し用メッセージを発行する
- 自身はメッセージループを回して待機する
- 相手の処理が終わると相手はメッセージを発行して自身のメッセージキューにメッセージが積まれる
- それを自身はメッセージループで取り出す
- メソッド呼び出しから制御が戻った状態になる
問題は自身はメッセージループを回して待機する間に、別の待機していたメソッド呼び出しから制御が戻ってくることがあるということです。まるでコルーチンのコンテキストスイッチですよね。
すなわち、シングルスレッドだけれども、シーケンシャルに処理されないことがあるわけです。
ここで他の処理と自身の処理で同一の状態を参照している、具体的には同じ変数に対して操作をしていると、まるでマルチスレッドプログラミングにおける競合状態に対する考慮と同様にことが必要になるわけです。
もちろんシングルスレッドなので同じ変数に対して操作していても、マルチスレッドプログラミングにおける競合状態のような問題が起きるわけではありませんが、自身のメソッド以外が自身のメソッドの処理が参照している状態を書き換えてしまうということが起こり得ます。
ここで厄介なのはマルチスレッドプログラミングにおいて通用する「とりあえずmutexでロックを確実に取る」ができないということです。
COM STAにおいてなぜmutexをとってはいけないか
先に、COMオブジェクトのメソッド呼び出しは、ウィンドウメッセージによって達成されると書きました。
つまり、呼び出したメソッドから処理が戻って来るには、自身のスレッドにウィンドウメッセージが投げられてきて、それを受け取る必要があります。そのためにはメッセージループがきちんと回っている必要があります。メッセージループについてはWin32APIでGUIを作るとかならず遭遇する、GetMessageしてTranslateMessageしてDispatchMessageしているあれを思い浮かべればいいと思います。
MSG msg;
for (;;)
{
int ret = GetMessage(&msg, nullptr, 0, 0);
if (ret == 0 || ret == -1)
break;
TranslateMessage(&msg);
DispatchMessage(&msg);
}
もしメッセージループ内で重たい処理が行われたり、ロックを取って待機したりなど、メッセージループが回るのを阻害してしまうと、呼び出したメソッドから処理が戻って来なくなることに繋がります。
PCを操作しているとたまに画面がフリーズして言うことを効かなくなったウィンドウができることがありますが、これはまさにメッセージループが回るのが阻害されている状況というわけです。
もしmutexを取ってしまうとどうなるのでしょうか。処理Aと処理Bが共有している変数aを参照するためにmutexを取ることを考えてみましょう
class Foo { int a; std::mutex mtx; void A() { std::lock_guard<std::mutex> lock(mtx); // #1 a += 1; // do something AnotherApartmentObject->SomeMethod1(); // #2 std::cout << a << std::endl; } void B() { std::lock_guard<std::mutex> lock(mtx); // #3 a += 2; // do something AnotherApartmentObject->SomeMethod2(); // #4 std::cout << a << std::endl; } };
処理Aの冒頭でmutexを取ります(#1)。そして別のアパートメントのメソッドを呼び出します(#2)。 このときメッセージループが回り始めます。
そうこうしていると処理Bが割り込んできました。 処理Bの冒頭でmutexを取ろうとします(#3)。しかし処理Aの冒頭(#1)で取得したmutexは開放されていないので、mutexがとれませんので、取れるまで待機します。
しかしながらこのときメッセージループもまた停止しています。
すると処理Aで呼び出した別のアパートメントのメソッドから処理が戻ろうとしてメッセージキューにメッセージが積まれるものの、メッセージを取り出せないので、処理Aは再開できません。つまり永遠に処理A冒頭で取得したmutex(#1)は開放できない状態になります。
これはデッドロックしていますよね。
こういったわけで、STAにおいてmutexを取るのはご法度というわけです。
じゃあstd::recursive_mutexをつかえばいいのでは?と思うかもしれません。たしかに同一スレッドからの再帰的なロック取得を許可するので、デッドロックは回避できます。しかしながら、今度はmutexで解決したかったであろう、自身のメソッド以外が自身のメソッドの処理が参照している状態を書き換えてしまう問題を解決できません。つまり再入の対策にならないわけです。
VS2015対応で苦しんだSTAと戦わずに済むはず(フラグ)
VS2015対応で何と戦ったのかについてはぜひ上記の記事を読んでいただきたいのですが、その時も問題になっていたのはSTAにおける「再入」という問題でした。
今回の要件で部分的な機能取り込みをしようとしているOptimal Biz Teleworkという製品は、ユーザーの稼働状況を取得するという処理の性質上、ユーザーセッションで動作させる必要があるものでした。ところがWindows Agentは基本的にはWindows Serviceなのでユーザーセッションの管理をするのは大変そうです。VS2015対応の記事で出てきていたUIAgentManagerとUIAgentはまさにこのユーザーセッションの管理に関わるコードでした。しかもSTAです。
しかし、つい2ヶ月くらい前の「再入」との戦いの経験があまりにも新鮮に思い起こせた私は、可能な限りMTAで処理を動かすと最初から決めていました。
VS2015対応で読んでいたコードのなかで、MTAからユーザーセッションの管理ができるClientHolderというクラスがすでに実装されていることを知っていた私は、要件に取り掛かる段階でこれを使うと決めていました。これでSTAと戦わずにすむ、勝ったな。そうやって私はフラグを立てたわけです。
ClientHolderはだいたいこんな感じの使い方ができるクラスです。TeleworkUserActivityLogCollectorは今回追加したCOMオブジェクトでユーザーセッションに生成したいものです。
// こういうのがメンバーにいるとして konata::com::git_ptr<TypeLib::IWtsSessionManager> m_wts; // https://github.com/egtra/konata std::shared_ptr<Helper::ClientHolder> m_holder; // 初期化 TypeLib::IWtsSessionManagerPtr wts = QueryService<TypeLib::Service::WtsSessionManager>(); m_wts = wts; // m_holderの初期化 if (!m_holder) { m_holder = std::make_shared<Helper::ClientHolder>( m_settings, // イベント受信用 m_wts.get(), // COMオブジェクト作成処理 [pwts = &m_wts](DWORD sessionId) { // WtsSessionManagerはGlobal Interface Tableを介さないとマーシャル出来ないらしい TypeLib::ITeleworkUserActivityLogCollectorPtr collector = Helper::CreateSessionObject<TypeLib::TeleworkUserActivityLogCollector>(pwts->get(), sessionId); return collector; }, Helper::TargetUser::AllUsers, Helper::TargetSession::AllActive ); } // m_holderを使った処理の例 for (auto&& pair : m_holder->GetClients()) { // WTSQuerySessionInformationW して WTSActive かみる if (!IsSessionWTSActive(pair.first)) continue; TypeLib::ITeleworkUserActivityLogCollectorPtr collector = pair.second; collector->Collect(); }
ClientHolderのセッションの管理の裏側にはVS2015対応で散々戦ったUIAgentManagerとUIAgentがいます。VS2015対応で改修影響範囲にClientHolderがいたので覚えていたというわけです。「進研ゼミでやったところだ!」みたいな感覚ですね。
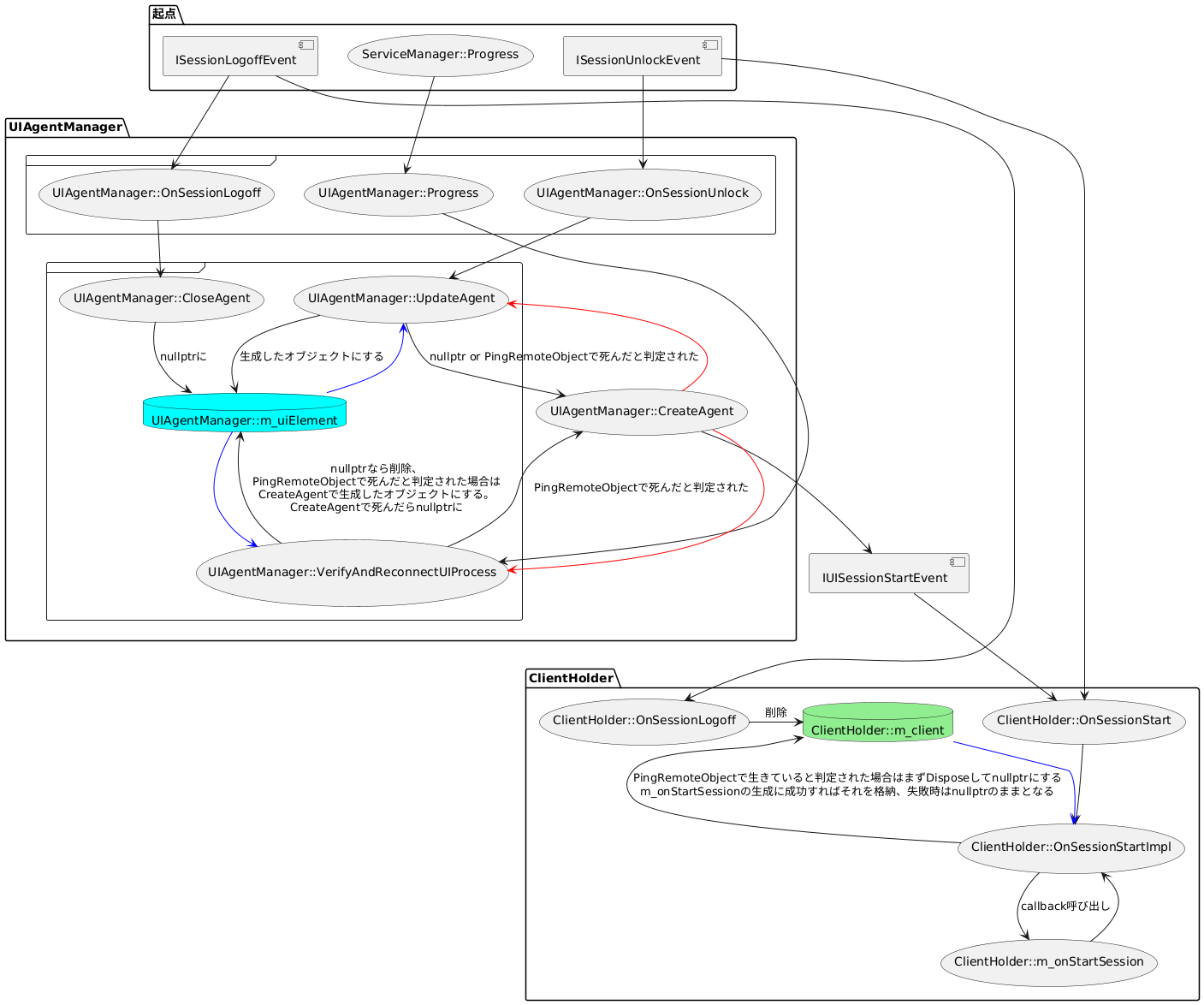
VS2015対応で倒したはずのCOMとの戦いは序章に過ぎなかった(フラグ回収)
ユーザーセッションの管理という実装が大変そうなところを比較的すんなり抜けて、実装を進めていくと問題に直面しました。
ユーザーの稼働状況を取得するという処理を一部移植するというのが今回の対応で、今回持ってくる処理には大きく時間がかかる処理は幸いにしてありませんでした。しかしながら、今後さらなる機能拡張が考えられる状況で、そのなかに時間がかかる処理が含まれるようになる可能性もありました。
Windows Agentを終了するようなとき、なるべくはやく終了してほしいと思うわけですが、時間が掛かる取得処理が動いているとなかなか終了できないということが考えられます。
そこで終了時には処理をキャンセルする処理を実装しようということになりました。キャンセルは協調的キャンセルとし、実装的には残念ながらC++20で追加されたstd::stop_tokenがまだ利用できないのでキャンセルフラグを自作しています。概ね次の記事の「自前の同期キャンセルフラグ実装」と同じです。
さて、ユーザーの稼働状況を取得するという処理の全体を見渡すと関係する処理が開始する契機が3つあることになります。
- 5分毎のタイマー契機: OnTimer
- Optimal Biz Teleworkは設計上、誤差なく5分間隔でログを上げる必要がある
- 管理サイトからの同期時:
ApplySetting->ApplySettingImpl- Biz管理サイトと同期して指示を受けてログ取得をするかしないかが決まる
- Biz終了時・認証解除時などからくるDispose呼び出し: raw_Dispose
- キャンセル処理
ここで誤算だったのが2つありました。
1つ目はBiz管理サイトと同期して指示を受けて処理を行うApplySettingがSTAで呼ばれるということでした。これをMTAにするにはWindows Agentの根幹に手をいれるような改修が必要そうです。
2つ目はキャンセルを実装するためのメソッドraw_DisposeもまたSTAで呼ばれるということでした。こちらも同種の処理が多数あるので1つ目ほどではないにせよ改修範囲が大きくなってしまいます。
一方でOnTimerはMTAで呼ばれます。
すると何が起こるのかというとSTAの再入の問題とマルチスレッドプログラミングにおける排他処理の問題の両方を同時に満足させる必要が出てきたわけです。どういうことでしょうか?コードの概形を見てみましょう。
STDMETHODIMP TeleworkUserActivityLogService::raw_Dispose() { } bool TeleworkUserActivityLogService::ApplySetting() { const auto setting = GetSetting(); // 略 // 別スレッドで動かして完了は待たない。内部的にはQueueUserWorkItemを呼び出してスレッドプールを使っている。 // thisを直接渡さないのは参照カウントを増やしてthisが死なないようにするため。 // また、ApplySetting()が実行されたタイミング(同期が実行されたタイミング)の設定値を使用するため、設定値を引数で渡す Async::RunTask(std::bind(&TeleworkUserActivityLogService::ApplySettingImpl, GetIntrusive(), *setting)); } void TeleworkUserActivityLogService::OnTimer() { // 略 } void TeleworkUserActivityLogService::ApplySettingImpl(const WindowsAgent::TeleworkUserActivityLogSetting& setting) { // 略 }
GetIntrusive()はCOMの参照カウントを操作するshared_from_this()みたいなものです。
ここで各メソッドが呼び出されるアパートメントを整理すると次のようになります。
- STA
raw_DisposeApplySetting
- MTA
OnTimerApplySettingImpl
STAで呼ばれるメソッド同士は同じスレッド上で動くため、排他処理を考慮する必要はありませんが、MTAで呼ばれるメソッド同士、STAで呼ばれるメソッドとMTAで呼ばれるメソッドの間では同じメモリー領域を操作するときには排他処理が必要です。つまりmutexを取る必要があります。
std::lock_guard<std::mutex> lock(m_mutex);
MTAで呼ばれるメソッド同士の排他制御はこれでいいです、簡単ですね。
ところがすでに述べた通りCOM STAにおいてmutexを取るのは御法度です。STAで呼ばれるメソッドとMTAで呼ばれるメソッドの間では同じメモリー領域を操作するときの排他処理は一体どうすればいいのでしょうか。
丸一日考えて進捗がなかったときはあまりにもわからないので、契機が3つであることと物理学の領域の三体問題という解決できない(正確には求積可能ではない)問題をかけて、COM STAと並列処理の三体問題(以下、三体問題)と社内で勝手に命名していました。今回もまたSTAと正面から向き合う必要が出てきたわけで、見事フラグ回収となりました。
結局この問題の解決の糸口を掴むだけに3営業日を溶かしました。糸口を掴んだ後も本当にそれで大丈夫なのか、まったく確証が持てません。だからといってそんな状態のコードを渡されたレビュワーも困ってしまいます。
三体問題にどう挑むのか
ちょうどその頃に、休日、家で見ていたYouTubeの動画の中で、とても役に立つことを訴えている動画に出会いました。よびのりたくみさんという方の動画なのですが、「場合分けはさせられるんじゃなくて、するもん」という言葉に「それだっ!」となったわけです。
(動画時間 8:10付近)
場合分けはさせられるんじゃなくて、こっちから望んでするんですよね。その意識を持つだけで、自分自身ですね、その、数学の実力はすごく上がりました、場合分けはさせられるんじゃなくて、するもんだなって思ってから。
(中略)
自分で場合分けできると思ったら、もう、普段使ってる問題集よりもたくさん場合分けしていいと思います。
(中略)
場合分けして解けるくらいだったら場合分けした方がいいと思います、実践的には。
というわけで、ひたすら場合分けして立ち向かうことにしました。
場合分けして修正して証明する
証明を全部書き上げるには6営業日かかりました(他の割り込みタスクもあったので実際にはその半分くらい)。
証明の様子
もう一回関連処理の契機を書いておくと次のとおりでした。
- 5分毎のタイマー契機: OnTimer
- Optimal Biz Teleworkは設計上、誤差なく5分間隔でログを上げる必要がある
- 管理サイトからの同期時:
ApplySetting->ApplySettingImpl- Biz管理サイトと同期して指示を受けてログ取得をするかしないかが決まる
- Biz終了時・認証解除時などからくるDispose呼び出し: raw_Dispose
- キャンセル処理
これに対して行った場合分けを箇条書してみるとこうなりました。20通り以上もあってお腹いっぱいになりそうです。
- 「1. 5分毎のタイマー契機」と「2. 管理サイトからの同期時」が同時に発生した場合
- 「1. 5分毎のタイマー契機」のほうが先行した場合
- 「2. 管理サイトからの同期時」のほうが先行した場合
- 「1. 5分毎のタイマー契機」と「3. Biz終了時・認証解除時などからくるDispose呼び出し」が同時に発生した場合
- 「1. 5分毎のタイマー契機」のほうが先行した場合
- (i) OnTimerがcollector->Collect()呼び出し中ではないとき
- (ii) OnTimerがcollector->Collect()呼び出し中のとき
- 「3. Biz終了時・認証解除時などからくるDispose呼び出し」のほうが先行した場合
- 「2. 管理サイトからの同期時」と「3. Biz終了時・認証解除時などからくるDispose呼び出し」が同時に発生した場合
- 「2. 管理サイトからの同期時」のほうが先行した場合
- (i) 管理サイトからの指示で収集を停止するとき
- (ii) すでに収集を行っているときの管理サイトとの同期のとき
- (iii) 管理サイトからの指示で収集を開始するとき
- (ア) raw_Disposeに処理が移る場合
- (イ) raw_Disposeに処理が移らない場合
- 「3. Biz終了時・認証解除時などからくるDispose呼び出し」のほうが先行した場合
- 「1. 5分毎のタイマー契機」と「2. 管理サイトからの同期時」と「3. Biz終了時・認証解除時などからくるDispose呼び出し」が同時に発生した場合
- 1->2->3
- (i) OnTimerがTeleworkUserActivityLogCollectorを呼び出していないとき
- (ii) OnTimerがTeleworkUserActivityLogCollectorを呼び出しているとき
- 1->3->2
- (i) OnTimerがTeleworkUserActivityLogCollectorを呼び出していないとき
- (ii) OnTimerがTeleworkUserActivityLogCollectorを呼び出しているとき
- 2->1->3
- (i) 管理サイトからの指示で収集を停止するとき
- (ii) すでに収集を行っているときの管理サイトとの同期のとき
- (ア) ApplySettingImplがロックを取得する場合
- (イ) OnTimerがロックを取得する場合
- (iii) 管理サイトからの指示で収集を開始するとき
- (ア) raw_Disposeに処理が移る場合
- (イ) raw_Disposeに処理が移らない場合
- 2->3->1
- 3->1->2
- 3->2->1
証明の中には言葉だけでは整理しきれず、plantumlのタイミング図を活用した場面もありました。
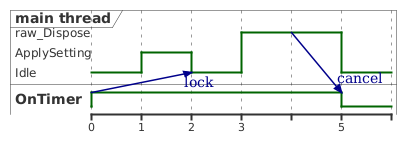
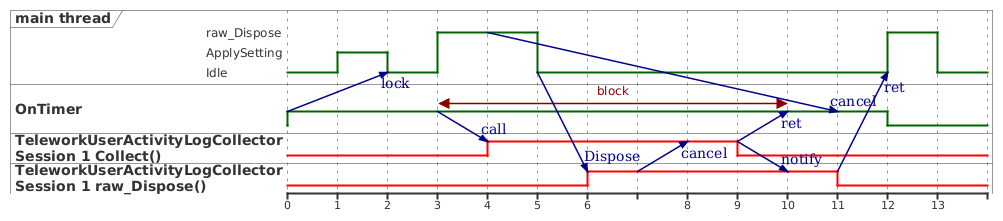
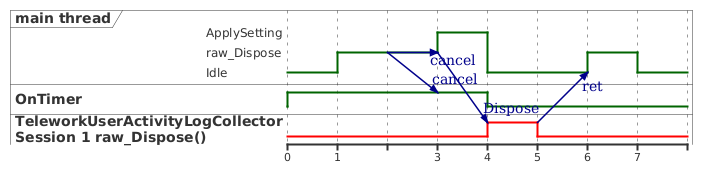

STAの再入やメッセージ待ち、キャンセルフラグの伝播の表現に非常に便利だったので、全国に何人いるかわからないCOM STAで苦しむ皆様もぜひ場合分けしたうえでplantumlでタイミング図を書いてみてください。
修正した内容
証明を書いていく中でコードの修正も同時に行っていました。
まず、各契機で共通して参照する変数としてm_holderというstd::shared_ptr<Helper::ClientHolder>型のメンバ変数がいました。
この変数に対する書き込み操作、つまりm_holder = <something>したりm_holder.reset()する操作はMTAなApplySettingImplで行われていました。
これをSTAなApplySettingに集約し、他の箇所ではm_holderをコピーしてshared_ptrの参照カウントを増やしてそれを使うようにしました。
// 再入中に`m_holder.reset()`されても大丈夫なようにコピーしておく const auto holder = m_holder; // 略 hodler->some_method();
こうすることで、STAなアパートメントでのみ書き込み操作をするということになります。同時に気がついたらm_holderの参照先がいなくなっていて、不正なメモリーアクセスをしてしまうという事故も防げます。
以前、並行並列処理の共有される状態はとりあえずshared_ptrのような参照カウンタがあるもので保持するべしという話を見たことがあるのですが、今回もそれが当てはまるケースでした。
STAなアパートメントでのみ書き込み操作をするということはどういうことが言えるかというと、
STAな他のメソッド呼び出しにおいて、m_holderを読み出しても競合状態にならないのでロックする必要が無いということが言えます。つまりBiz終了時・認証解除時などからくるDispose呼び出し(=raw_Dispose)はロックする必要がないということです。
次に依然としてm_holderを参照するApplySettingでロックを取得する必要があるわけですが、ここではロックを確保できるか試して、確保できなければリトライさせる手法を採用しました。つまりこうなります。
bool TeleworkUserActivityLogService::ApplySetting() { // 略 std::unique_lock<std::mutex> lock(m_mutex, std::try_to_lock); if (!lock) { // 1分後くらいに先送り、see ServiceManager::Progress this->raw_Expire(); return false; } // 略 }
std::try_to_lockの効果で、ロックを確保できないときは!lockがtrueになってif文の中に入ります。
raw_Expireは自身のサービスのタイマーををシグナル状態にします。こうすることで約1分毎に多数のサービスを走査しているループでApplySettingがもう一度呼び出されます。
これならロック確保待ちで長時間ブロッキングしないことが期待できるので、STAからでも呼び出せます。
COM STAと並列処理の排他制御に同時に立ち向かうための処方箋
長々書いたことをまとめてみると次のように集約されます。
- 共有される状態は
std::shared_ptrのような参照カウンタがある機構で保持しましょう - 共有される状態の書き込み操作は1契機に集約しましょう
- STAのメソッド同士は排他制御する必要が無いことを利用して、共有される状態の書き込み操作はSTAなメソッドで行いましょう
- STAなメソッドでmutexのロックを取る必要があるときは、
std::try_to_lockを用いて、ロックが取れないときは少し時間を開けてリトライしましょう - 問題が複雑になってきたときは、場合分けしましょう
- 図式化して整理するときはplantumlのタイミング図が便利です
常にいつでも使える対処法ではないものばかりですが、設計するときに意識はしておきたいものだと思います。
おわりに
VS2015対応でCOM STAとは戦い尽くしたつもりでしたが、むしろ今回が本番といった様相を呈していました。「場合分けはさせられるんじゃなくて、するもん」という言葉に励まされながら証明を書いて乗り切りましたが、一方でそれをレビュワーは読んで理解する必要に迫られたわけでして、チームメンバーの協力に心から感謝したいと思います。
こうした戦いを今後避けるためにはやはりCOM STAを捨ててMTAにするために、Windows Agentの根幹に手をいれる必要がありそうです。俺達の戦いはこれからだ!。
OPTiMではC++のコードを読み書きするのが楽しいと思えるエンジニアや、もうすぐ2025年という今になってCOMと戦うことに喜びを感じるエンジニアも募集していると思います。少しでも興味がありましたら下記フォームよりご応募ください。