概要
YJITは「Versioning of basic blocks」と「Lazy code generation」をキーコンセプトに据えて設計されていて、古典的なJITコンパイラがメソッドベースでのみ判断するのとは対照的に、Basic Blockのような細かい単位で判断を行う。
YJITがRubyに入ったことで、YJITユーザーはrustcのライフサイクルを気にする必要が出てきた。
はじめに
Optimal Biz開発チームの戸舘です。私は業務では主にRubyを使ってWebアプリケーションの開発をしつつ、一方では C++ と COM を用いてWindows Serviceアプリケーションを開発しています。そんなC++erです。
2022年9月8~10日に開催されたRubyKaigi 2022がつい昨日のことのように思う今日このごろですが、まもなくRubyKaigi 2023が松本で5月11~13日にかけて開催されます。
RubyKaigi 2023 - RubyKaigi 2023
OPTiMではRubyKaigi 2022についての記事を執筆したわけですが、そのときはYJITについては単体の記事で出したいという思いから、概略だけにとどめていました。
この記事ではRubyKaigi 2022において、YJITがどのように紹介されたのかを改めて振り返っていこうと思います。
もちろんあれから1年近くが経過していますから、この記事が公開される時点ではすでに古い情報となっているでしょうが、なるべく変動の激しくないであろうところを焦点に、解説を試みています。
YJITの概略(前回の記事より)
そもそもJIT(just-in-time)コンパイルとは、ネイティブコードにコンパイルを行う速度的ハンデを背負った上で、生成されるネイティブコードの速さを持って結果的に実行速度を上げることを目指すものです。
RubyでJITをする試みは今回が初めてではありません。Ruby 2.6で追加されたMJITでは、Ruby VMのコードを利用しつつ、gcc/clangの恩恵を受けて最適化されたネイティブコードを得てそれを実行することができます。
YJITはRuby 3.1.0で追加されたの新しいJITで、MJITより優れた遅延コード生成を行います。Ruby 3.2.0ではARM64アーキテクチャに対応します。ARM64を捨てることはApple対応しないのと同じことであると断言しており、意欲的なARM64対応が進んでいます。
basic block
プログラムの最適化という文脈において、basic block(基本ブロック)という単語が出てきます。
Wikipediaの説明を引用してくると
基本ブロック(きほんブロック、英: Basic Block)は、コンピュータにおいて、一つの入り口(すなわち、内部のコードが他のコードの分岐先になっていない)と一つの出口を持ち、内部に分岐を含まないコードを指す。
とあります。
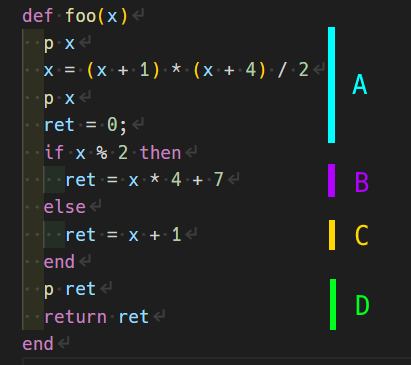
例えば次のコードを見てみます。
def foo(x) p x x = (x + 1) * (x + 4) / 2 p x ret = 0; if x % 2 then ret = x * 4 + 7 else ret = x + 1 end p ret return ret end
これを基本ブロックごとに色分けすると概ね次のA~Dのようになります。
tail duplication
tail duplicationとは、末尾のブロックを複製して、前に処理されるブロックに結合することを言います。
先のコードを例にすると、Dの部分を複製してD'を作り、BにDを、CにD'を統合することになります。

tail duplicationは一般にsuper-blockの形成の過程で行われます。
super-block
スーパーブロック(super-block)とは、頻繁に実行されるパスを表現するために用いられる、基本ブロック(basic block)の直線的なシーケンスであり、次のような性質を持ちます。
- シーケンスの先頭ブロックからのみたどれる
- super-blockに向かってjmpしてこない
- どの基本ブロックからも離脱できる
- jmpしてsuper-blockから離脱できる
- (スーパーブロック内の基本ブロックは、コード上で連続している必要はない)
結果として、実行がスーパーブロックに到達した場合、そのスーパーブロック内のすべての基本ブロックが実行される可能性が非常に高い、と期待できます。これによってsuper-block以外のパスの実行時間が増大する可能性を増加させる可能性がある代わりに、実行頻度の高いsuper-blockに対してより積極的な最適化を可能とします。
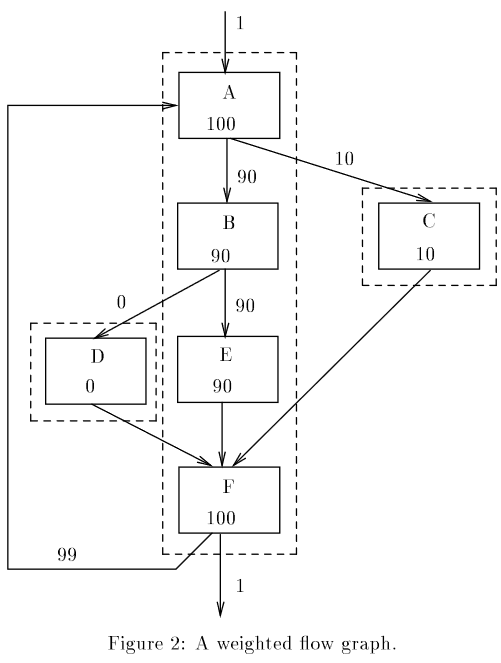
まずFigure2(下記論文より引用)に示しているのは、basic blockのシーケンス図です。図中の矢印に添えられた数字は任意の方法でプログラムを実際に実行してプロファイリングして得た、basic block間の遷移回数です。この中で最も頻繁に実行されるパスは{A, B , E , F}であることは明々白々でしょう。
点線の枠はトレースとよばれ、順番に実行される傾向にある基本ブロックをグループ化したものです。super-blockとは異なり、先頭以外のbasic blockにジャンプしてくる可能性があります。
ここからsuper-blockを形成するためにtail duplicationを行います。
{A, B , E , F} のトレースに入ってくる経路はFに対して入ってくる2箇所なので、D,Cの参照先をF'にすることで、Fに入る経路を無くします。その結果が下のFigure5(下記論文より引用)です。これによって{A, B , E , F}はsuper-blockになります。

この論文への疑問
ところで読んでもよくわからなかったのですが、super-blockからjump-outするのはいいのにjump-inするのはだめとしているのはなぜなんでしょうね?一般にjmp命令は、CPUの命令パイプラインを壊しキャッシュミスを起こすために遅いことが知られていると思います。一方でjump-inしてくる場合、それ自体は同様にして遅いわけですが、その可能性があるからと言って、jumpせずに一連のコードとして実行されるときに対して最適化を阻害すると言うのは、いまいちしっくり来ません。
もしかしてbasic blockを並べ替えてre-orderするとかそういうことを念頭においているのでしょうか・・・?
参考: C/C++におけるプロファイリングとは
先程、「任意の方法でプログラムを実際に実行してプロファイリングして得た、basic blockが実行された頻度」と言いましたが、C/C++においてこれはどのように行われるのでしょうか?
C/C++の一般的な処理系は、プログラムをコンパイルしてから実行するタイプです。つまりそのままでは実行時の情報をコンパイル時にフィードバックできません。
これに対する解決策がProfile-Guided Optimization (PGO)です。
- プロファイル生成機能を埋め込んでプログラムをビルドする
- それをビルド者が一般的なユースケースになるように実行してプロファイルを生成する
- プロファイル結果を含めて再度ビルドして完成
PGOビルドはこんにちにおいて、別に目新しいものではなくずいぶんと昔から利用できるものでした。
2014年頃からMicrosoftがVisual StudioのCommunity版をリリースしたことでますます一般的に利用できる最適化となっています。
rigayaの日記兼メモ帳 x265 ビルド ~ Visual Studio PGOビルド
2回のコンパイルと試験実行という、実質的なビルド工程の増大を犠牲に、JITに負けない、実行速度の最大化が得られます。
YJITの特徴
まず前提として、動的型付け言語において、あるコードの任意の変数がどのような型を取り得るかを知るには、プログラム全体の解析が必要であり、極めてコストが大きいという問題があります。ネイティブコードを生成するには当然型情報が必要ですが、この型の評価はなるべく最小化したいわけです。
これを満たすためのYJITの主要な概念は「Versioning of basic blocks」と「Lazy code generation」です。
Versioning of basic blocks
basic blockの中がどういう型で評価されたかは文脈によって変化します。この文脈ごとに、basic blockを特殊化します。
・・・C++erは特殊化と言われるとすぐにtemplateを思い浮かべてしまうので、つまりこういう感じですかね・・・?依存する変数の型ごとにネイティブコードを吐き出せるみたいなイメージなのかなと解釈しました。
namespace flip_flop { struct source_location { uint_least32_t line; uint_least32_t column; std::string_view file_name; std::string_view function_name; constexpr source_location(const std::source_location& loc) : line(loc.line()), column(loc.column()), file_name(loc.file_name()), function_name(loc.function_name()) {} auto operator<=>(const source_location&) const = default; }; } namespace std { // std::hashの特殊化 template<> struct hash<flip_flop::source_location> { size_t operator()(const flip_flop::source_location& l) const { using flip_flop::detail::hash_combine; size_t ret{}; hash_combine(ret, l.line); hash_combine(ret, l.column); hash_combine(ret, l.file_name); hash_combine(ret, l.function_name); return ret; } }; }
文脈ごとに、basic blockを特殊化することで、複数バージョンのbasic blockが作られうることになります。これによって型情報の蓄積と伝播が達成できるようになります。
特殊化にあたってコンパイルの単位は大きい方がいいので、必要に応じてtail duplicationを実施します。
Lazy code generation
YJITは古典的なJITコンパイラとは異なり、メソッド毎のJITではなくより細かい単位であるbasic block単位でJITを行えます。
実行中のプロファイリングの結果、同じメソッド内でも実際にはほとんど通過しないbasic blockが存在すると、そこはJITコンパイルを行いません。
JITコンパイルしないということは、コストがかかる型情報の評価をYJITでやらなくていいので、高速化に繋がります。つまりJITコンパイルが本当に必要になるまで、型の評価を遅延できるわけです。
同様にして、tail duplicationも遅延されます。つまり上で述べていたsuper-blockの形成とは少し異なって、必要なところだけ、必要なときにtail duplicationするということでしょう。
YJITがARM64をサポートするために
ARM64を捨てることはApple対応しないのと同じことであると断言しており、意欲的なARM64対応が進んでいます。
Cで書かれていたYJITの初期実装を改めて、Rustで書き直されました。
また、複数のプラットフォームに対応するために、IR層を導入しました。これはbasic block単位のIRであることが想定されています。また生成したIRはコンパイルが終わると破棄するのでメモリー消費を抑えています。
ref: - Building a Lightweight IR and Backend for YJIT - RubyKaigi 2022
YJITの全体像
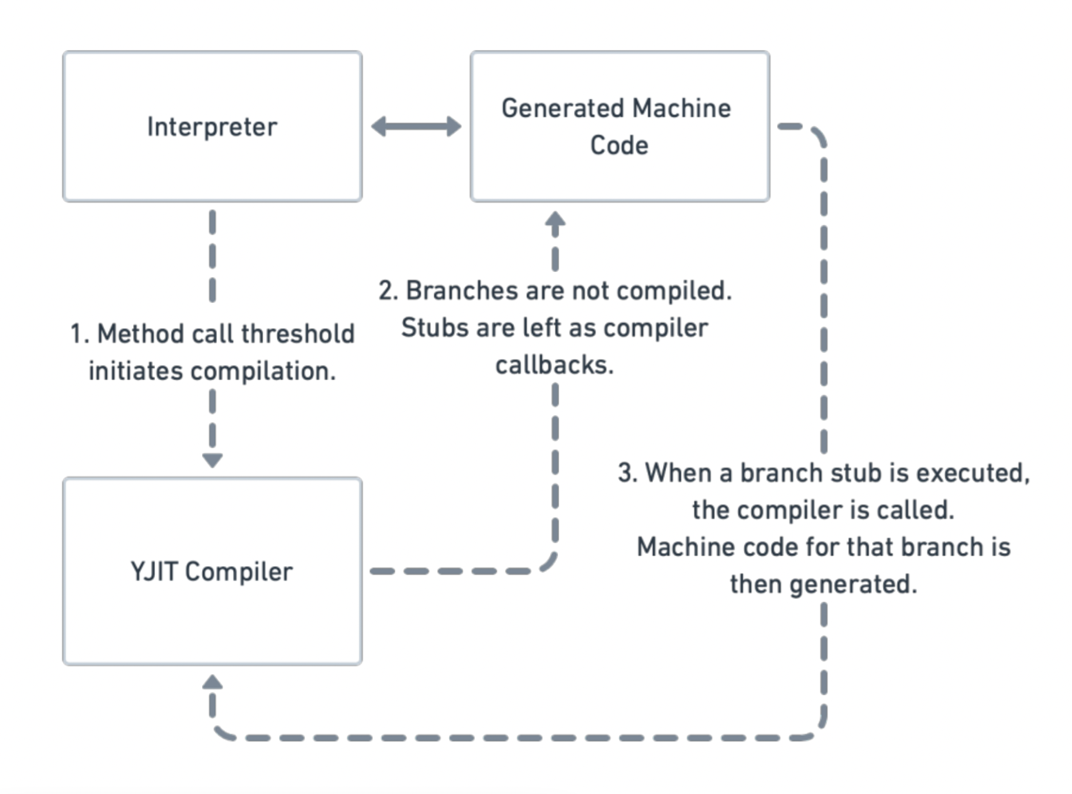
maximecb. YJIT RubyKaigi 2022 slides - Google スライド, 2023-05-08閲覧.
YJITが動き出すトリガーはメソッドがしきい値を超える回数呼び出されることです。
ここから上述したbasic blockごとの解析を始めるために、メソッドをStubします。このStubの呼び出しがあると、ネイティブコードの生成が開始されていきます。
RubyにおけるYJIT
RubyはずっとCで頑張ると思っていたところ、Rustで書きたいと来たのがYJITだったようです。
YJITはoptionalな存在であること、YJITチームの生産性がRuby全体に対して重要であることからRustで書いていいといったところ、恐るべき速度で開発が行われた、とMatzは語っています。
ref: - Contribute to Ruby - RubyKaigi 2022
rubybuildからみたYJIT
YJITを使うためには--enable-yjitオプションを付けた上で、rustcが必要となります。
開発環境はもちろんとして、アセットコンパイルする環境にもrustcが必要となるわけです。
CRubyを動かすためにgccのライフサイクルをこれまで気にしてきたわけですが、これに加えてrustcのライフサイクルも気にする必要が出てきたということです。
ref: - Why is building the Ruby environment hard? - RubyKaigi 2022
という話だったのさ
他にもYJITの話はありましたが、一番気になるところはここまでに述べたような話がRubyKaigi 2022では展開されました。
発表の概ね全てはYoutubeで公開されています。
(318) RubyKaigi 2022 - YouTube
おわりに
まもなくRubykaigi2023が開催されます。そして今年もまたYJITに関する発表が行われるようです。そんなときにこの記事を見て予習/復習しておくと、きっと皆様の理解の助けとなるでしょう。
- Fitting Rust YJIT into CRuby - RubyKaigi 2023
- Optimizing YJIT’s Performance, from Inception to Production - RubyKaigi 2023
- Ruby JIT Hacking Guide - RubyKaigi 2023
OPTiMでは、YJITのようなRubyの低レイヤーな話に興味がある人材も募集しています。