

はじめに
こんにちは。技術統括本部、DX推進部の張です。 留学生で中国から来て、日本文化が大好きで日本の企業に働くことになった社会人一年目です。
個人的なニュースは、最近サイバーパンク2077にハマっていて、よりいい画質のためグラボ買い替えを考えたところビットコインブームに遭遇して、グラボがほぼ欠品になっていることです。
さて、今回はAmazon Timestreamというサービスを試していまして、その結果を紹介いたします。
要約
- 2020年10月に時系列専用DB:Amazon Timestreamがリリースされました
- DBのアップロード、クエリ時の性能を調査しました
- 公式Go言語SDKを使ってDBに230万レコードのデータを入れてみました
- このデータをもとにいくつかのクエリを実行し、レスポンスを測りました
- SQLがサポートされている時系列DBとして十分使えます
目次
背景
業務中にロボットの時系列データを扱うため自社製品の OPTiM Cloud IoT OS(以下CIOS)時系列DB をデータストアとして使用しています。直近の案件でDBに対する集約機能やSQL文でクエリを実行するニーズがあり、最近のAmazon Timestreamを技術調査しました。
CIOS についてご興味がある方はぜひこちらにご覧ください。
時系列とは
時系列(timeseries)データとは、時間情報(timestamp) を持った一連の値のことです。例としては、気温の遷移や降水状況などの気象観測や交通の状態、土地利用の変遷など、ある一時期の状態を表すような、時間的に変化した情報を持つデータのことです。
時系列データを分析することによって、気候パターンの解析や天気予報、交通状況の監視などができます。
時系列DBは、時系列データを扱うデータベースです。
今回の案件では、ロボットの動作状況を把握するため、ロボットから出力されたデータ(各アームの角度、電流値など)を時間ベースで時系列DBに保存したいです。また、そのデータに対して集約、可視化、または解析するユースケースです。
Amazon Timestreamの特徴
Amazon Timestream とは、2020年10月頃AWSによりリリースされた時系列特化データベースです。公式では、RDB(リレーショナルデータベース)の最大 1,000 倍の速度と 10 分の 1 のコストで、1 日あたり数兆ものイベントを保存、分析できると紹介されています。
Amazon Timestreamは次のような特徴があります。*1
- 低コストで高パフォーマンス
- 自動スケーリングによるサーバーレス
- データのライフサイクル管理
- 簡素化されたデータアクセス
- 時系列専用(これが今回のポイント)
- 平滑化、近似、集計などの時系列関数が組み込まれており、SQL を使用して分析できる
- 常時暗号化
ユースケース
他の時系列DBとほぼ同様に、時間にかかわるデータを分析するイメージです。具体的には:*2
- IoT アプリケーション
- IoTデバイスによって生成される時系列データを分析
- 例えばスマートホームで室温が落ちたら自動的に通知をする・エアコンを付けるなど
- DevOps アプリケーション
- 例えば CPU やメモリの使用率をモニタリングし、インスタンスの使用量を最適化する
- 分析アプリケーション
- データを平滑化、近似、補間、集計などによってデータを処理する
テーブルコンセント
Amazon Timestreamでは以下のコンセプトがあります。*3
- Time series: 時間間隔にわたって記録された1つ以上のデータポイントのシーケンス
- Record: 時系列のデータポイント
- Dimension: 時系列のメタデータを説明する属性
- 例えばIoTデバイスの場合、デバイスIDやメーカー
- Amazon DynamoDBと違い、事前にスキーマ(カラム)を指定する必要がない
- Measure: 測定されている値
- 例えばIoTデバイスの場合、温度や湿度
- Timestamp: レコードが発生する時刻
テーブルのコンセプトは図のように示しています。
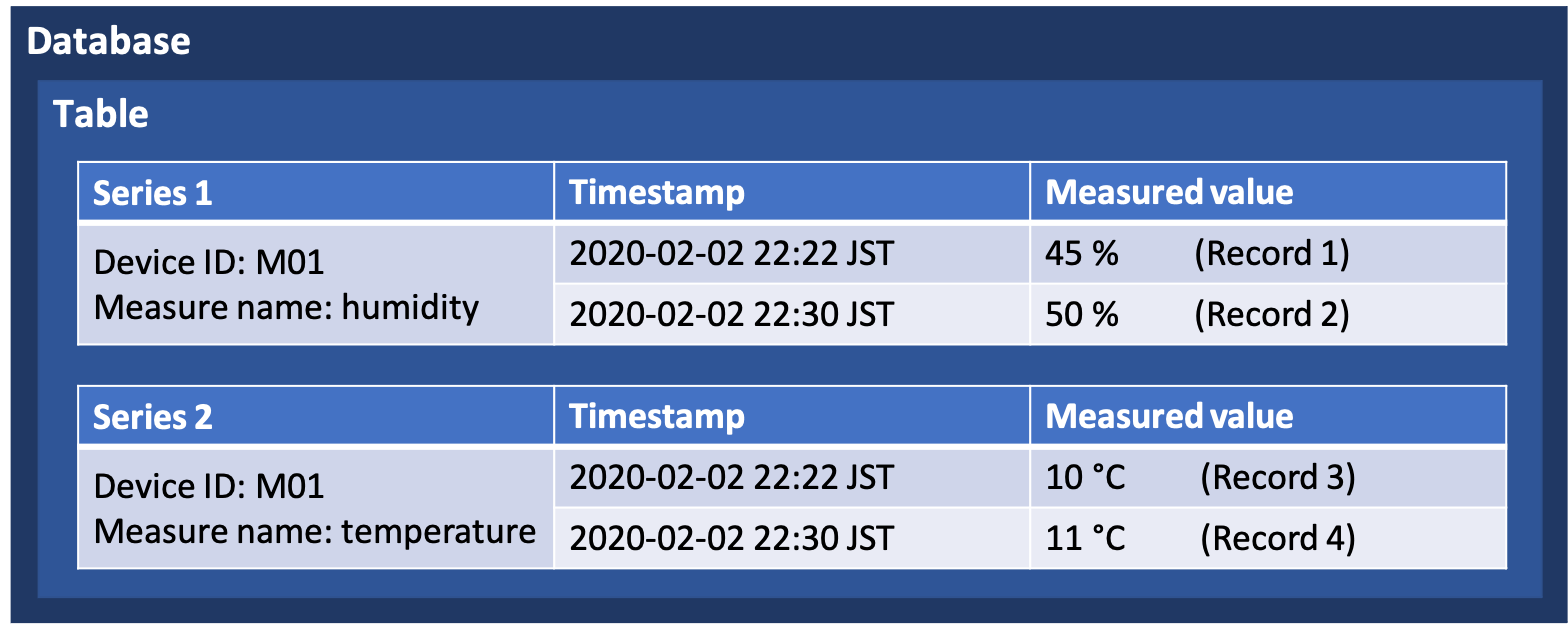
例えばM01という温度計が存在し、ある時間で測定した温度と湿度をDBに保存するとこうなります
| device_id | device_name | time | temperature | humidity |
|---|---|---|---|---|
| M01 | 温湿度計 | 2020/02/02 22:22 | 10 | 45 |
それに対して、Amazon Timestreamの場合はこうなります
| device_id(Dimension) | device_name(Dimension) | time | measure_name(measure) | measure_value::double |
|---|---|---|---|---|
| M01 | 温湿度計 | 2020/02/02 22:22 | temperature | 10 |
| M01 | 温湿度計 | 2020/02/02 22:22 | humidity | 45 |
今回の案件では、同じ時間のカラムがあわせて42個あって(温度計が40個あるイメージ)、CIOS時系列DBではスキーマ指定によって1レコードで42カラムのデータをストアすることができますが、Amazon Timestreamにすると42レコードになり、テーブルがかなり縦にふえてしまっています。
Amazon Timestreamの調査
ここではAmazon Timestreamに対するデータのアップロード、保存、性能テストを行いました。
データのアップロードについて
- 保存できるデータタイプ
- BIGINT
- 64-bit int
- BOOLEAN
- true / false
- DOUBLE
- 64-bit float
- VARCHAR
- 文字列、最大 2KB
- BIGINT
- (SDKを使う場合)DBにデータをPOSTするには制限がある
- 1回のPOSTは100レコードまで
- 1レコードでは1つの値にしか保存できない
- 同じ時間で複数の値を保存するならそれぞれを時間を付けて保存しなければならない(例えばこの時間の温度と湿度を両方保存するなら2レコードになる)
- プログラムでPOSTするなら1秒で4~5回POSTができる
- これ以上の性能を求めるなら平行処理を使うべき
- 1回のPOSTは100レコードまで
実際使ってみると、確か保存できるタイプは普段のDBより少ないですが、時系列DBのユースケース的にはあまり問題ありません。
ただ気になるのは、1回のリクエストには最大100レコードまでしか保存できないところです。今回の案件のように一度大量なデータをアップロードするケースにはやや煩雑だと思います。
データの保存について
アップロードされたデータは、まずメモリ(Memory store)に保存され、一定時間を経過したらマグネッティクストア(Magnetic store)に移動されます。テーブルごとで設定できます。
- Memory store retention
- メモリ内のデータはにどれぐらい保存される
- 最短1時間、最大1年まで設定でる
- この時間を超過するデータはMagnetic storeに移動される
- Magnetic store retention
- マグネッティクストア内のデータはどれぐらい保存される
- この時間を超過するデータは消去される
- 最短1日、最大200年まで設定できるが、永続にはなれない
- 注意点
- DBに挿入可能なデータはMemory store retention時間内のデータのみ
- 仮にMemory store retentionを
1dayに設定した場合、2日前のデータを挿入するとエラーになる
リージョンについて
残念ながら、東京リージョンではAmazon Timestreamを使えません(2021/2/26時点)
- Amazon Timestreamサービスを使うならこれらのリージョンから選べます
- 米国東部 (バージニア北部)
- 米国東部 (オハイオ)
- 欧州 (アイルランド)
- 米国西部 (オレゴン)
料金について
https://aws.amazon.com/jp/timestream/pricing/より、2021/2/26時点、バージニア北部の場合
- 書き込み
- 1 KB サイズの書き込み 100 万件 0.50 USD
- メモリストア
- 格納された GB 時間あたりの料金 0.036 USD
- 月あたりに換算すると 25.9 USD
- SSD ストア(近日提供予定)
- 格納された GB 日あたりの料金 0.01 USD
- 月あたりに換算すると 0.30 USD
- マグネティックストア
- 格納された GB 月あたりの料金 0.03 USD
- クエリ
- 1 GB あたりのスキャン量 0.01USD
課金項目がいくつかありますね。特にストアがいくつかの選択肢があるので見積もる際には難しいかもしれません。
Amazon Timestreamにアクセスしてみます
さて、ここでは実際にAmazon Timestreamにアクセスしてみましょう!
公式ではこれらの方法でアクセスできますが、今回はウェブコンソールとGo言語のSDKを使ってみます。
- ウェブコンソール:AWS Console
- クエリの実行
- クエリの保存
- 結果確認
- SDK:AWS SDKs
- Java
- Go
- Python
- Node.js
- .NET
- AWS CLI
- API
前準備
- AWSCLI V2 をインストールする
$ curl "https://awscli.amazonaws.com/awscli-exe-linux-x86_64.zip" -o "awscliv2.zip" $ unzip awscliv2.zip $ sudo ./aws/install You can now run: /usr/local/bin/aws --version $ aws --version aws-cli/2.1.13 Python/3.7.3 Linux/4.19.128-microsoft-standard exe/x86_64.ubuntu.20 prompt/off
- AWS アカウント登録
- IAMユーザの準備
- サインイン後、Myセキュリティ資格情報にアクセス、アクセスキーを作成する
- 参考: https://qiita.com/miwato/items/291c7a8c557908de5833
- aws-cliの初期設定
- awsのアクセスキーを用意する
- 参考: https://qiita.com/reflet/items/e4225435fe692663b705
$ aws configure AWS Access Key ID [None]: {アクセスキー(各自)} AWS Secret Access Key [None]: {シークレットアクセスキー(各自)} Default region name [None]: us-east-1 Default output format [None]: json
- サンプルコードをクローン
- Goモジュールinit
$ cd sample_apps/go
$ go mod init go_sample
go: creating new go.mod: module go_sample
データ挿入
crud-ingestion-sample.goを実行すると、devopsのデータベースとhost_metricsのテーブルが作成され、サンプルデータが挿入されます。
$ go run crud-ingestion-sample.go # DBを作成する Creating a database, hit enter to continue Database successfully created Describing the database Describe database is successful, below is the output: { Database: { Arn: "arn:aws:timestream:us-east-1:01234567890:database/devops", CreationTime: 2020-12-21 09:01:32.36 +0000 UTC, DatabaseName: "devops", KmsKeyId: "arn:aws:kms:us-east-1:01234567890:key/12345678-hoge-hoge-hoge-123456789012", LastUpdatedTime: 2020-12-21 09:01:32.36 +0000 UTC, TableCount: 0 } } Skipping update database because kmsKeyID was not provided # DBを表示する Listing databases List databases is successful, below is the output: { Databases: [{ Arn: "arn:aws:timestream:us-east-1:01234567890:database/devops", CreationTime: 2020-12-21 09:01:32.36 +0000 UTC, DatabaseName: "devops", KmsKeyId: "arn:aws:kms:us-east-1:01234567890:key/12345678-hoge-hoge-hoge-123456789012", LastUpdatedTime: 2020-12-21 09:01:32.36 +0000 UTC, TableCount: 0 }] } # テーブルを作成する Creating a table Create table is successful Describing the table Describe table is successful, below is the output: { Table: { Arn: "arn:aws:timestream:us-east-1:01234567890:database/devops/table/host_metrics", CreationTime: 2020-12-21 09:01:33.7 +0000 UTC, DatabaseName: "devops", LastUpdatedTime: 2020-12-21 09:01:33.7 +0000 UTC, RetentionProperties: { MagneticStoreRetentionPeriodInDays: 73000, MemoryStoreRetentionPeriodInHours: 6 }, TableName: "host_metrics", TableStatus: "ACTIVE" } } # テーブルを表示する Listing tables List tables is successful, below is the output: { Tables: [{ Arn: "arn:aws:timestream:us-east-1:01234567890:database/devops/table/host_metrics", CreationTime: 2020-12-21 09:01:33.7 +0000 UTC, DatabaseName: "devops", LastUpdatedTime: 2020-12-21 09:01:33.7 +0000 UTC, RetentionProperties: { MagneticStoreRetentionPeriodInDays: 73000, MemoryStoreRetentionPeriodInHours: 6 }, TableName: "host_metrics", TableStatus: "ACTIVE" }] } # テーブルを更新する Updating the table Update table is successful, below is the output: { Table: { Arn: "arn:aws:timestream:us-east-1:01234567890:database/devops/table/host_metrics", CreationTime: 2020-12-21 09:01:33.7 +0000 UTC, DatabaseName: "devops", LastUpdatedTime: 2020-12-21 09:01:34.849 +0000 UTC, RetentionProperties: { MagneticStoreRetentionPeriodInDays: 2555, MemoryStoreRetentionPeriodInHours: 24 }, TableName: "host_metrics", TableStatus: "ACTIVE" } } # データを挿入する Ingesting records Write records is successful Ingesting records with common attributes method Ingest records is successful Ingesting records and set version as currentTimeInMills, hit enter to continue First-time write records is successful Retry same writeRecordsRequest with same records and versions. Because writeRecords API is idempotent, this will success. hit enter to continue Retry write records for same request is successful Upsert with lower version, this would fail because a higher version is required to update the measure value. hit enter to continue Error: RejectedRecordsException: One or more records have been rejected. See RejectedRecords for details. { RespMetadata: { StatusCode: 419, RequestID: "JF2XQW5EESN26F3LITHUXBTS7Y" }, Message_: "One or more records have been rejected. See RejectedRecords for details.", RejectedRecords: [{ ExistingVersion: 1608543656435, Reason: "The record version 1608543656434 is lower than the existing version 1608543656435. A higher version is required to update the measure value.", RecordIndex: 0 },{ ExistingVersion: 1608543656435, Reason: "The record version 1608543656434 is lower than the existing version 1608543656435. A higher version is required to update the measure value.", RecordIndex: 1 }] } Upsert with higher version as new data is generated, this would success. hit enter to continue Write records with higher version is successful Exiting from here to avoid table and database cleanup being called.
クエリ
クエリを実行するにはQuery editorとSDKの2択があります。Query editorはSQL文をサポートしていますが、SDKはプログラムで自動化することが可能になります。
Query editorによりアクセス
- 標準SQL文がサポートされている
- リンク
まずはデータベースとテーブルを選択します。

次に右上のQuery tableを選択します。
するとクエリエディタの画面がみえます。
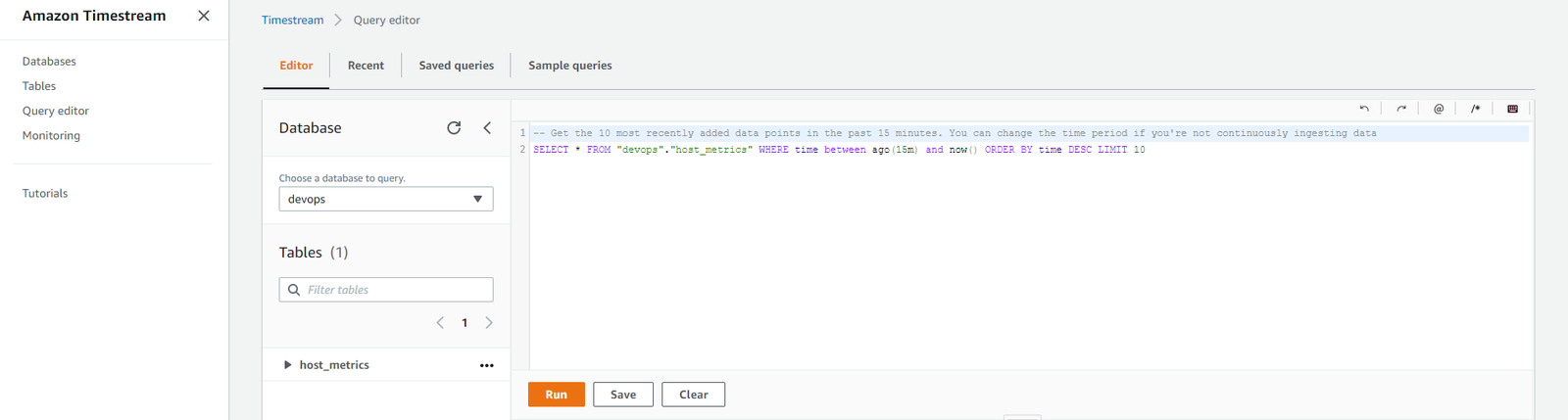
ここでは先ほど挿入したデータを見てみましょう。
-- Get the 10 most recently added data points in the past 15 minutes. You can change the time period if you're not continuously ingesting data SELECT * FROM "devops"."host_metrics" WHERE time between ago(15m) and now() ORDER BY time DESC LIMIT 10
Runを押すと下にこのような結果がでます。これでクエリが成功します。
| hostname | az | region | measure_value::double | measure_name | time |
|---|---|---|---|---|---|
| host1 | az1 | us-east-1 | 14.5 | cpu_utilization | 2020-12-21 09:40:56.000000000 |
| host1 | az1 | us-east-1 | 50.0 | memory_utilization | 2020-12-21 09:40:56.000000000 |
SDK
query_sample.goを実行するとクエリが実行できる- 結果はページングでくる
- 1ページにおおよそ3000レコード
$ chmod 777 *.sh $ ./devops_init.sh devops host_metrics # init QueryInput: { QueryString: "SELECT hostname, count(*) as hostcount\nFROM devops.host_metrics\nWHERE measure_name = 'cpu_utilization'\n AND time > ago(2h)\nGROUP BY hostname\nORDER BY count(*) DESC"} Current query status: { CumulativeBytesMetered: 10000000, CumulativeBytesScanned: 192, ProgressPercentage: 100 } Metadata: [{ Name: "hostname", Type: { ScalarType: "VARCHAR" } } { Name: "hostcount", Type: { ScalarType: "BIGINT" } }] Data: host1, 3 Number of rows: 1 $ ./devops.sh devops host_metrics hostname # これでクエリが走ります QueryInput: { QueryString: "SELECT region, az, hostname, BIN(time, 15s) AS binned_timestamp,\n ROUND(AVG(measure_value::double), 2) AS avg_cpu_utilization,\n ROUND(APPROX_PERCENTILE(measure_value::double, 0.9), 2) AS p90_cpu_utilization,\n ROUND(APPROX_PERCENTILE(measure_value::double, 0.95), 2) AS p95_cpu_utilization,\n ROUND(APPROX_PERCENTILE(measure_value::double, 0.99), 2) AS p99_cpu_utilization\nFROM devops.host_metrics\nWHERE measure_name = 'cpu_utilization'\n AND hostname = 'hostname'\n AND time > ago(1d)\nGROUP BY region, hostname, az, BIN(time, 15s)\nORDER BY binned_timestamp ASC" } Current query status: { CumulativeBytesMetered: 10000000, CumulativeBytesScanned: 0, ProgressPercentage: 100 }
性能テスト
ここではAmazon Timestreamの各種性能をテストしています。前提条件は以下に示します。
- おおよそ8時間分、合計で2353008レコードのデータにたいしてテストする
- データ間隔は500ms
- 56024レコード
- 1レコードに42カラム
データ挿入時間
Ingested 2353008 records to the table. It took 12627403 milliseconds.- 1回POSTに最大100レコードまで
- およそ6万回POST、3.5時間をかかる
- 平均で1分間300POST・30000レコード
1分間~3万レコードのスピードはやや遅いと感じますね。
クエリがかかる時間
ここではよく使うクエリのレスポンス時間を測ってみました。全部Query Editorの時間を記録しています。
まずはデータを全件取得するのをためしています。(あまりユースケースとして考えなれないですが)
| Query | Scanned size | Time |
|---|---|---|
| 全ての生データを取得する | 222.16 MB | 27.83 sec |
sensor1の生データを取得する |
4.89 MB | 3.224 sec |
次に1カラムに対して集計してみます
| Query | Scanned size | Time |
|---|---|---|
sensor1のカラム数を計算する |
4.89 MB | 1.351 sec |
sensor1の平均値 |
4.89 MB | 1.373 sec |
sensor1の合計値 |
4.89 MB | 1.338 sec |
sensor1の最大値 |
4.89 MB | 1.360 sec |
sensor1の最小値 |
4.89 MB | 1.329 sec |
ここからの集約機能が今回の案件のメインユースケースになります。
ここのテストデータの間隔が500msですので、1日分、または数か月分の生データそのまま処理するのは負荷が重くなります。そのため、一定時間内(仮に10sごと)の平均値を求め、粒度を荒めにするため集約機能を使います。
| Query | Scanned size | Time | Rows returned |
|---|---|---|---|
| 全件データに対して10sごとに集約 | 222.16 MB | 4.6 sec | 1000+ |
| 全件データに対して1minごとに集約 | 222.16 MB | 3.8 sec | 1000+ |
| 全件データに対して5minごとに集約 | 222.16 MB | 3.4 sec | 1000+ |
sensor1に対して10sごとに集約 |
4.89 MB | 2.513 sec | 1000+ |
sensor1に対して1minごとに集約 |
4.89 MB | 1.1 sec | 377 |
sensor1に対して5minごとに集約 |
4.89 MB | 0.6590 sec | 76 |
結論として:
- 1レコード~1KBぐらい
- Scanned sizeは実際処理したデータのサイズ
FROMとWHEREで絞ったデータ- これをもとに課金される
- Scanned sizeが大きいほどレスポンスが遅くなる
- 結果のレコード数が多いほどレスポンスが遅くなる
各クエリ文とレスポンス時間の詳細はこちらです。
クエリ時間: 全件取得
- 全ての生データを取得する
- 222.16 MB scanned
- 27.83 sec
SELECT * FROM devops.host_metrics ORDER BY time DESC
sensor1の生データを取得する- 4.89 MB scanned
- 3.224 sec
SELECT * FROM devops.host_metrics WHERE measure_name = 'sensor1' ORDER BY time DESC
クエリ時間: 集約
sensor1のカラム数を計算する- 4.89 MB scanned
- 1.351 sec
SELECT COUNT(measure_value::DOUBLE) as count_sensor1 FROM devops.host_metrics WHERE measure_name = 'sensor1'
sensor1の平均値を計算する- 4.89 MB scanned
- 1.373 sec
SELECT AVG(measure_value::DOUBLE) as avg_sensor1 FROM devops.host_metrics WHERE measure_name = 'sensor1'
sensor1の合計値を計算する- 4.89 MB scanned
- 1.338 sec
SELECT SUM(measure_value::DOUBLE) as sum_sensor1 FROM devops.host_metrics WHERE measure_name = 'sensor1'
sensor1に対して最大値を求める- 4.89 MB scanned
- 1.360 sec
SELECT MAX(measure_value::double) as max_sensor1 FROM devops.host_metrics WHERE measure_name = 'sensor1'
sensor1に対して最小値を求める- 4.89 MB scanned
- 1.329 sec
SELECT MIN(measure_value::double) as min_sensor1 FROM devops.host_metrics WHERE measure_name = 'sensor1'
sensor1に対して10sごとに集約- 4.89 MB scanned
- 2.513 sec
- 1000+ rows returned
SELECT bin(time, 10s) as binned_time, avg(measure_value::double) as avg_sensor1 FROM devops.host_metrics WHERE measure_name = 'sensor1' GROUP BY bin(time, 10s) ORDER BY binned_time
sensor1に対して1minごとに集約- 4.89 MB scanned
- 1.1 sec
- 377 rows returned
SELECT bin(time, 1m) as binned_time, avg(measure_value::double) as avg_sensor1 FROM devops.host_metrics WHERE measure_name = 'sensor1' GROUP BY bin(time, 1m) ORDER BY binned_time
sensor1に対して5minごとに集約- 4.89 MB scanned
- 0.6590 sec
- 76 rows returned
SELECT bin(time, 5m) as binned_time, avg(measure_value::double) as avg_sensor1 FROM devops.host_metrics WHERE measure_name = 'sensor1' GROUP BY bin(time, 5m) ORDER BY binned_time
- 全データに対して10sごとに集約
- 222.16 MB scanned
- 4.6 sec
- 1000+ rows returned
SELECT bin(time, 10s) as binned_time, measure_name, avg(measure_value::double) as avg FROM devops.host_metrics WHERE measure_value::double IS NOT NULL GROUP BY bin(time, 10s), measure_name ORDER BY binned_time, measure_name
- 全データに対して1minごとに集約
- 222.16 MB scanned
- 3.8 sec
- 1000+ rows returned
SELECT bin(time, 1m) as binned_time, measure_name, avg(measure_value::double) as avg FROM devops.host_metrics WHERE measure_value::double IS NOT NULL GROUP BY bin(time, 1m), measure_name ORDER BY binned_time, measure_name
- 全データに対して5minごとに集約
- 222.16 MB scanned
- 3.4 sec
- 1000+ rows returned
SELECT bin(time, 5m) as binned_time, measure_name, avg(measure_value::double) as avg FROM devops.host_metrics WHERE measure_value::double IS NOT NULL GROUP BY bin(time, 5m), measure_name ORDER BY binned_time, measure_name
MemoryとMagneticの反応速度の検証
最後にMemory storeとMagnetic storeの反応速度を検証してみました。結果として、あまり差が見えないが、実際データがどこにあるのを見えないため、今回の結果をMagnetic storeの反応速度として考えてください
- データを入れる:12/24夕
- 1回目の検証:12/25朝
- 2回目の検証:12/28夕
- テーブルの設定
- Memory store retention--1 day
- Magnetic store retention--200 years
sensor1のカラム数を計算する- 1.351 sec (12/25)
- 1.258 sec (12/28)
sensor1の平均値を計算する- 1.373 sec (12/25)
- 1.652 sec (12/28)
sensor1の合計値を計算する- 1.338 sec (12/25)
- 1.548 sec (12/28)
まとめ
今回はAWSの新サービスAmazon Timestreamを試してみました。時系列特化で、SQLもサポートされているのでデータ集約のユースケースに助かると思います。が、データ保存の制限や、Magneticストアの存在などの煩雑なところもあります。
最後にAmazon Timestreamのメリットとデメリットをまとめてみました。
Amazon Timestream のメリット
- サーバーレスで構築できる
- DB自体をサービスとして提供しているため、サーバーが不要
- 集約機能がついている
- 特定な条件でデータを集約することができる
- SQLが使える
- 条件付きでクエリができる
- スキーマはない
- Amazon DynamoDBのように事前スキーマを決める必要はない
- DimensionやMeasureは可変なのでアップロード時に追加は可能
- MemoryとMagneticのストアが存在する
- 保存時間として、Memoryは最大1年、Magneticは最大200年まで
- 高速のMemoryストレージと低速だが安価のMagneticストレージが存在し、ユースケースにあわせて選択できる
- 加えてSSDが近日提供予定になっているため、より豊富な選択が期待できる
- SDKの結果が数が多くとページングで来る
- クエリの結果が数千個以上になると、結果は1ページおよそ3000レコードで戻る
- メモリーのストレスが比較的に小さくなる
Amazon Timestream のデメリット
- データ保存に制限がある
- 1回POSTでは最大100レコードまで
- Go言語で確認した結果、1秒に4~5回POSTができる
- 大量アップロードには平行処理をするべき
- 1レコードで1つのmeasure_valueしか保存できない、配列は不可
- 保存できるデータは4種類しかない
- BIGINT
- BOOLEAN
- DOUBLE
- VARCHAR
- Memory store retentionの設定期間外のデータは挿入不可
- リアルタイムでデータを投入するのは問題ないが、オフラインの環境で収集したロボットのログを後から一括投入したいユースケースがあって、その際に課題になる
- 東京リージョンでは利用できない
- レコード削除はできない
- 削除するにはテーブルごと削除するか、Magneticのデータ保存期限になると削除される
- SDKで数多いデータを処理する際にページングデータを扱う処理が課題になる
- 料金見積もりが難しい
- 料金はデータ量、保存時間、storeタイプ(MemoryかMagneticか)、クエリ回数などとかかわるため
おまけにAmazon Timestreamを調べているときに見つけた情報を添付します。
オプティムはエンジニアを募集しています!!