こんにちは、R&Dチームの河野(@ps3kono)です。深層学習モデルの開発を担当しております。
今回は、画像分類、画像検査、顔認識や異常検知など様々な分野に利用されている深層距離学習(Deep Metric Learning)について紹介したいと思います。
Deep Metric Learningとは
深層距離学習(Deep Metric Learning)とは、サンプル間の距離(metric)または類似度(similarity)に基づいてクラスごとに分離されるよう、入力データを特徴量空間への変換を学習させる手法です。距離学習の目的は、同じクラス(intra-class)のサンプル間の距離を小さくしながら、異なるクラス(inter-class)のサンプル間の距離を大きくすることです。古典的距離学習の代表的な手法としては、マハラノビス距離学習(Mahalanobis Distance Metric Learning)が挙げられます。深層学習の発展に伴い、深層学習と距離学習を組み合わせた様々な深層距離学習手法が提案されています。
定番のクラス分類と距離学習によるクラス分類の違い
まずは、深層学習によるクラス分類の仕組みについて、簡単に説明します。クラス分類用の畳み込みニューラルネットワーク(CNN)の基本構造は、図1のように特徴量抽出(feature extraction)とクラス分類(classification)に分けられます。特徴量抽出の部分は、複数の畳み込み層(convolutional layer: CONV)とpooling層から構造され、最終的にflatten層で一次元化されます。このプロセスで入力画像が特徴ベクトルに変換され、この特徴ベクトルはEmbeddingと呼ばれることがあります。クラス分類の部分では、入力された特徴ベクトルで分類を行い、各クラスの所属確率を予測結果として出力します。定番のCNNでは、この部分が一つまたは複数の全結合層(FC)で構造され、出力されたlogitsをsoftmax関数でクラス所属確率(probability)に変換します。次は、argmax関数で最も確率の高いクラスに予測します。(※ logitsとは、unnormalized log probabilitiesと呼ばれることがあります。)

定番のクラス分類と距離学習によるクラス分類の違いは、特徴量抽出部分を学習させる手法にあります。定番のクラス分類の学習ではintra-classとinter-classのサンプル間の距離を考慮せず全結合層で分離可能な(separable)特徴量を取り出すよう特徴量抽出ネットワークを学習させることです(図2)。クラス分類部分は一つのFC層で構造された場合、線形的に分離可能な特徴量を得られます。通常のクラス分類では訓練データに各クラスのサンプル数が十分含まれた場合に高い精度を達成できますが、訓練サンプルの少ないクラスまたは未知クラスがある場合には適していません。一方、距離学習による学習手法は意図的にinter-classのサンプル間の距離を大きくして、intra-classのサンプル間の距離を小さくするように学習させるため、識別的な(discriminative)特徴量を得ることができます(図2)。定番の学習手法と比較すると、intra-classのクラスターがよりコンパクトで、inter-class間の距離がより離れ、識別性の高い特徴量空間へ変換することができるようです1。そのため、各クラスのサンプルが少ないときや未知クラスがあるときでも十分な性能を発揮でき、顔認識や異常検知タスクなどでよく用いられています。

なお、距離学習の目的は識別的な特徴量を抽出することであり、クラス分類の他にクラスタリングタスクにも適用されています。クラス分類の部分は、必ずしもFC層で行う必要がありません。これについては、後述します
距離学習の進化
1. 対照的(contrastive)アプローチ
このアプローチでは、直接的にintra-classのサンプルを引き寄せてinter-classのサンプルを押しのけるように設計された損失関数を利用します。重要な要素は、ネットワーク構造、損失関数とサンプル選択です。まずは、サンプル選択について説明してから、代表的な学習手法ついて紹介します。
サンプル選択(sample selection)
対照的アプローチでは、直接的にサンプル間の距離でロスが計算されたため、サンプル組み合わせの選択はモデル訓練の成功と収束性に大きな影響を与えます。また、全ての可能なサンプル組み合わせで訓練すると、非常に計算量と時間がかかるため、効果的かつ効率的な学習のためには有益なサンプル組み合わせを選択することが重要です。代表的な手法は図3に示されます。簡単なサンプル組み合わせ(Easy negative mining)は、訓練に効果が少なく、時間と計算リソースの無駄使いに繋がると先行研究2で分かっていました。そのため、対照的アプローチの距離学習ではsemi-hardまたはhard negative miningがよく使われているようです。詳細については、「Deep metric learning: A survey」3の論文をご参考してください。

上記の図では、は基準となるサンプル(anchor)で、
は
と同じクラス(positive)のサンプルで、
は異なるクラス(negative)のサンプルとなります。
はサンプル
と
の間の距離です。マージン(
)は、正の定数であるハイパーパラメータです。
代表的な学習手法
Contrastive loss
Contrastive lossは、2006年に次元削減(Dimensionality Reduction)の目的で提案され4、一緒に使われる代表的なネットワーク構造はSiamese networkです(図4)。2枚の画像ペアを入力して、共有重み(shared weights)のネットワークで特徴量を抽出し、その距離()によってネットワークを学習させます。intra-classのペア(positive)を入力したときは距離を最小化するように学習し、inter-classのペア(negative)を入力したときは、距離を最大化するようネットワークを学習させます。損失関数は、下記のとおりです。
と
は、
-th入力画像のペアです。
はペアのラベルであり、positiveペアの場合は0でラベルされ、negativeペアの場合は1でラベルされます。マージン(
)は、正の定数であるハイパーパラメータです。上記の式によると、positiveペアを入力する場合は、
になるよう学習させ、negativeペアを入力する場合は
になるよう学習させます。ただし、クラス内またはクラス間の距離はクラスごとに異なり、大きく変動する可能性があるため、すべてのnegativeペアに一定のマージンを適用することは不適切だと思われます。
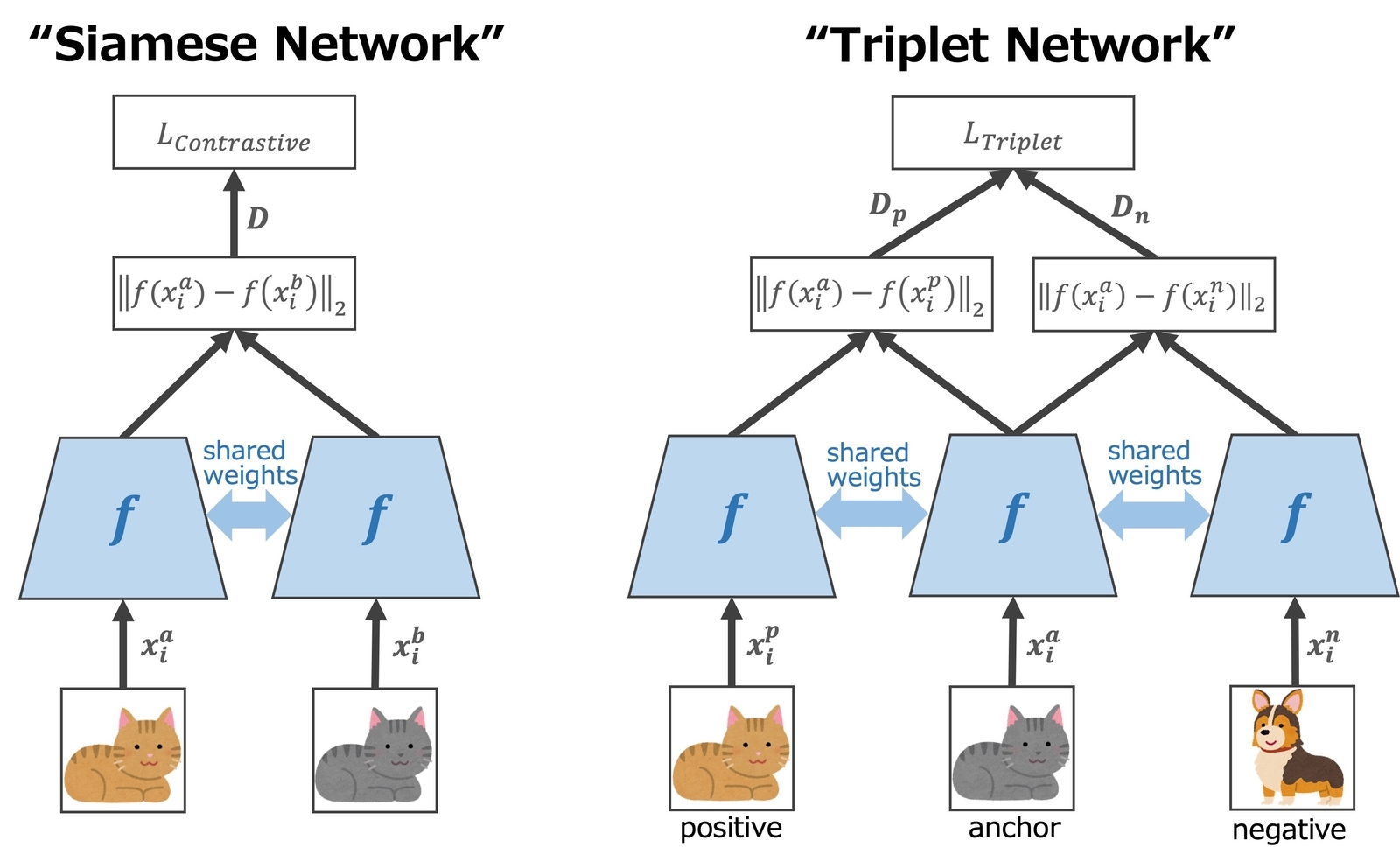
Triplet loss
Triplet lossでは、相対距離にマージンが適用されたため、Contrastive lossにおけるマージンの課題に対処することができます。Contrastive lossのように絶対距離にマージンをかけるのではなく、3枚組の入力画像でpositiveペアとnegativeペアの相対距離を算出し、それにマージンをかけます。つまり、Contrastive lossではnegativeペアをマージンの距離よりも離れるように学習させることですが、Triplet lossではnegativeサンプルとの距離をpositiveサンプルとの距離よりもマージン
の距離以上遠くなるよう学習させることです。同時で、intra-classのサンプルを引き寄せてinter-classのサンプルを離れようとすることができます。現在でも広く使われている距離学習手法のようです。
先行研究では、Triplet lossの損失関数としていくつかの微妙な違いのある式が使用されていましたが、その中によく引用されたのはWang et al.(2014)5のようです。その損失関数は下記の式で表されます。
、
、
は
-thサンプル組の基準となるanchor画像、positive画像とnegative画像です。この論文ではHinge lossと呼ばれましたが、最近の研究では同様な式をTriplet lossと呼ばれることが多いようです。FaceNetの論文20は、上記の式をもとにして最小化される損失関数をTriplet lossとして提案しました。下記の式では、最小損失をゼロに設定しています。
なお、上記の2つの論文では、サンプル間の距離を比較するために正規化された特徴量を用いています。Triplet lossと一緒に使われている代表的なネットワーク構造はTriplet networkです(図4)。
さらなる改善と進化
Triplet lossの主な制限の一つは、ロスを計算するためにanchorとあるクラスからのnegativeサンプルとしか比較されず、他クラスのnegativeサンプルが無視されることです。例えば、クラスA〜Eがあるとしたら、-thの反復で、クラスAのサンプルがanchorとして選ばれ、クラスBのサンプルがnegativeサンプルとして選ばれた場合、クラスAとクラスBの間の距離のみでロス計算しネットワーク重みを更新することになります。この制限を克服することを目的として、複数クラスのnegativeサンプルを同時に比較できる損失関数がいくつか提案されています。Quadruple loss、Structured loss、N-pair loss、NT-Xent loss(N-pair lossの改良版6)、Magnet loss、Clustering loss、Mixed lossなど。詳細については、参考文献3,7をご参照してください。もう一つの問題は、クラス内とクラス間のサンプル間の距離はクラスごとに異なるため、上記のように一定のユークリッド距離のマージンを指定することが不適切だと思われます。この問題を解決するためにスケールに依存しないAngular lossが提案されました8。この損失関数は、距離の代わりにサンプル間の角度を比較します。
また、損失関数の改善以外にも、Distance Weighted Sampling9やDeep Adversarial Metric Learning10などのnegative miningを改善する方法がいくつか提案されています。
対照的アプローチの問題点
- 学習の成功と収束性はサンプル選択に大きく依存し、アルゴリズム設計に手間がかかります。
- 慎重なサンプル選択が必要なため、アルゴリズムが複雑になる傾向があります。
- サンプル間の距離でロスを計算するため、入力になっているサンプルの組数が劇的に増加します。
- サンプル組の中またはmini-batchの中でサンプル間の距離を比較して重みを更新するため、グローバルではなくローカル情報で学習することになります。(この問題を解決するために、Clustering lossとMagnet lossが提案されましたが、精度の問題や複雑さにより人気がなかったようです)
2. Softmaxをベースにしたアプローチ
このアプローチは近年(2016年以降)に提案され、クラス分類用のSoftmax lossに基づいた手法です。Softmax lossの式は、下記のとおりとなります。
は
-thサンプルの特徴量であり、
-thクラスに所属しています。
と
は
-th列の重みとバイアスです。
Softmax lossは、同クラスのサンプル間の類似度を高めながら他クラスの類似度を低くするように強制しないため、得られた特徴量でのクラス識別性能は低いという課題があります。それを対処するために、いくつかの損失関数が以下のように提案されています。
代表的な学習手法
Center loss
2016年に、同クラスのサンプル間の距離を短縮するよう特徴量とそれに対応するクラスの中心位置との距離でペナルティを課すCenter lossがWen et al.(2016)1で提案されました。上記の対照的アプローチのような直接的にサンプル間の距離を比較する学習手法と違って、このアプローチではグローバルな情報(クラス中心位置)を利用して学習することが可能になり、さらに面倒なサンプル選択の工夫が不要になります。Center lossの損失関数()は下記のとおりで、訓練時にはSoftmax lossに加算した損失関数(
)を使われています。
は
-thサンプルの正解クラス(
-thクラス)の中心位置です。各クラスの中心位置(
)はmini-batchごとで更新され、2つの損失関数のバランスをとるためにパイパーパラメータ
が導入されました。クラス中心位置の不適切な定義や更新の困難さなどによりCenter lossはあまり普及しませんでしたが、以下のようなState-of-the-Art手法の発展に大きく影響を与えました。
SphereFace
SphereFaceの論文11では、Softmax lossで学習した特徴量には固有の角度分布があることが示唆され、Center lossのようにユークリッド距離で比較するよりも、角度距離で比較すべきだと提案されました。損失関数はSoftmax lossをベースにし、以下のように改良されています。
1. バイアス()をゼロにし、
になるよう重み(
)を列で正規化する。
2. 識別力を高めるようハイパーパラメータとしてMultiplicative angular margin()を導入する。
その結果、SphereFaceの損失関数は以下となります。
は、
-thサンプルの特徴量です。
は重みの
-th列であり、概念的に
-thクラスの中心位置だと考えられます。Angular margin(
)は特徴量(
)と重みの
-th列との角度(
)に対してのみ適用されます。この手法では、特徴量が正規化されず重みのみが正規化されます。ネットワーク構造はFig.5と似ていますが、特徴量の正規化とスケーリング部分はありません。なお、他手法の損失関数と容易に比較できるよう、一般化された式ではなく上記の式で説明しました。
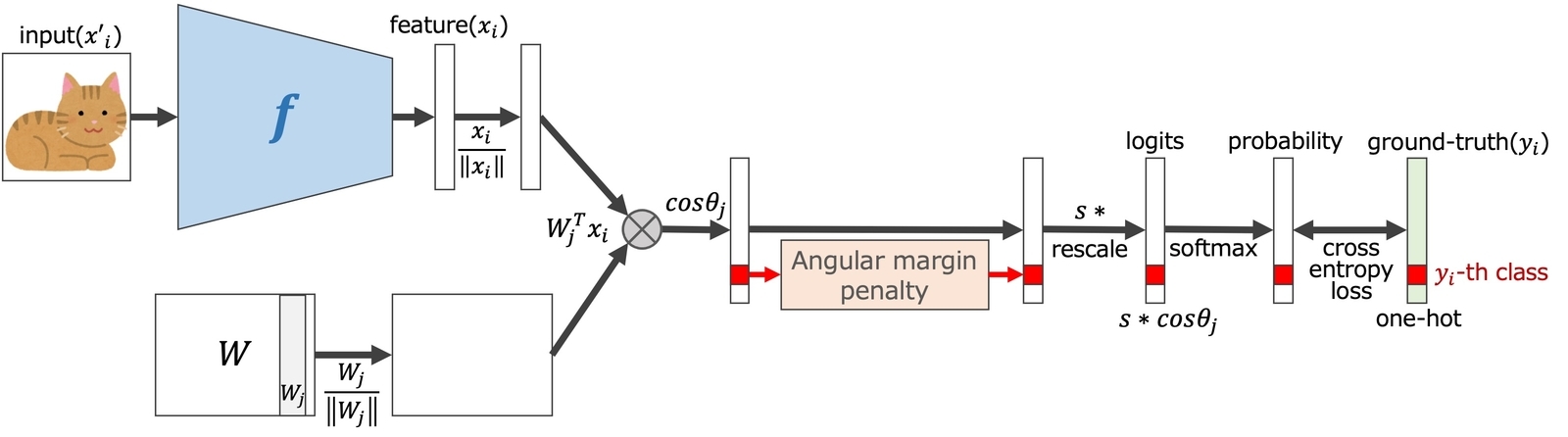
CosFace
CosFace12では、SphereFaceアルゴリズムが下記のように改良されました。
1. 重み()と同様に特徴量(
)を正規化する。SphereFaceと同様に
のため、 最後のFC層の出力は
になる。
は特徴量
と
-thクラスの中心位置 (
)との角度距離となる。つまり、
は特徴量
と
-thクラスの中心位置とのコサイン類似度である。
2. スケーリングパラメータ()をハイパーパラメータとして導入することで、収束性を向上させる。
3. さらに識別力を高めるために、Cosine marginをAngular marginとして導入する。Cosine marginはMultiplicative angular marginと違ってによって変化したり、
で消失したりしないため、全てのサンプルに一貫して適用することが可能。SphereFaceと同様に、Cosine marginは特徴量(
)と正解クラスの中心位置(
)とのコサイン類似度(
)に対してのみ適用される。
ネットワークの構造は図5と同様であり、損失関数は以下のように表せます。
ArcFace
ArcFace13の損失関数は、CosFaceとほとんど似ていて、ただ一つの違いはマージンの定義です。コサイン空間ではなく、直接的に角度空間でマージンを加算したため、線形な分離境界を確保できます。このマージンは、Additive angular marginと呼ばれます。ネットワークの構造は図5に示し、損失関数は以下のとおりです。
ArcFaceとCosFaceでは、スケーリングパラメータとマージン
のハイパーパラメータがあり、性能を最適化するために適切な値に設定する必要があります。また、ArcFaceの論文では、SphereFaceとCosFaceとArcFaceを組み合わせた損失関数を提案しており、その組み合わせた損失関数は以下に示します。
は SphereFace のMultiplicative angular margin、
は ArcFace のAdditive angular margin、
は CosFace のCosine marginに相当します。
さらなる改善と進化(2019年以降)
- AdaCos(2019年)14の論文では、スケーリングパラメータ
とマージン
のパラメータ調整の効果について徹底的に評価され、それらのハイパーパラメータを自動的に調整するAdaCos lossを提案されました。
- Circle loss(2020年)15は、類似度スコアに応じてペナルティの強さを調整し、動的にペナルティを適用する損失関数です。対照的アプローチとSoftmaxをベースにしたアプローチ用の損失関数が提案されました。
- ArcFaceの改良版
- MagFace(2021年)19は、顔認識専用に提案され、得られた特徴量は高い識別性を持つだけでなく、特徴ベクトルの大きさによって顔画像の質を示すことができます。学習時には、簡単なサンプルはクラス中心位置に引き寄せられ、難しいサンプルは押しのけられます。
推論
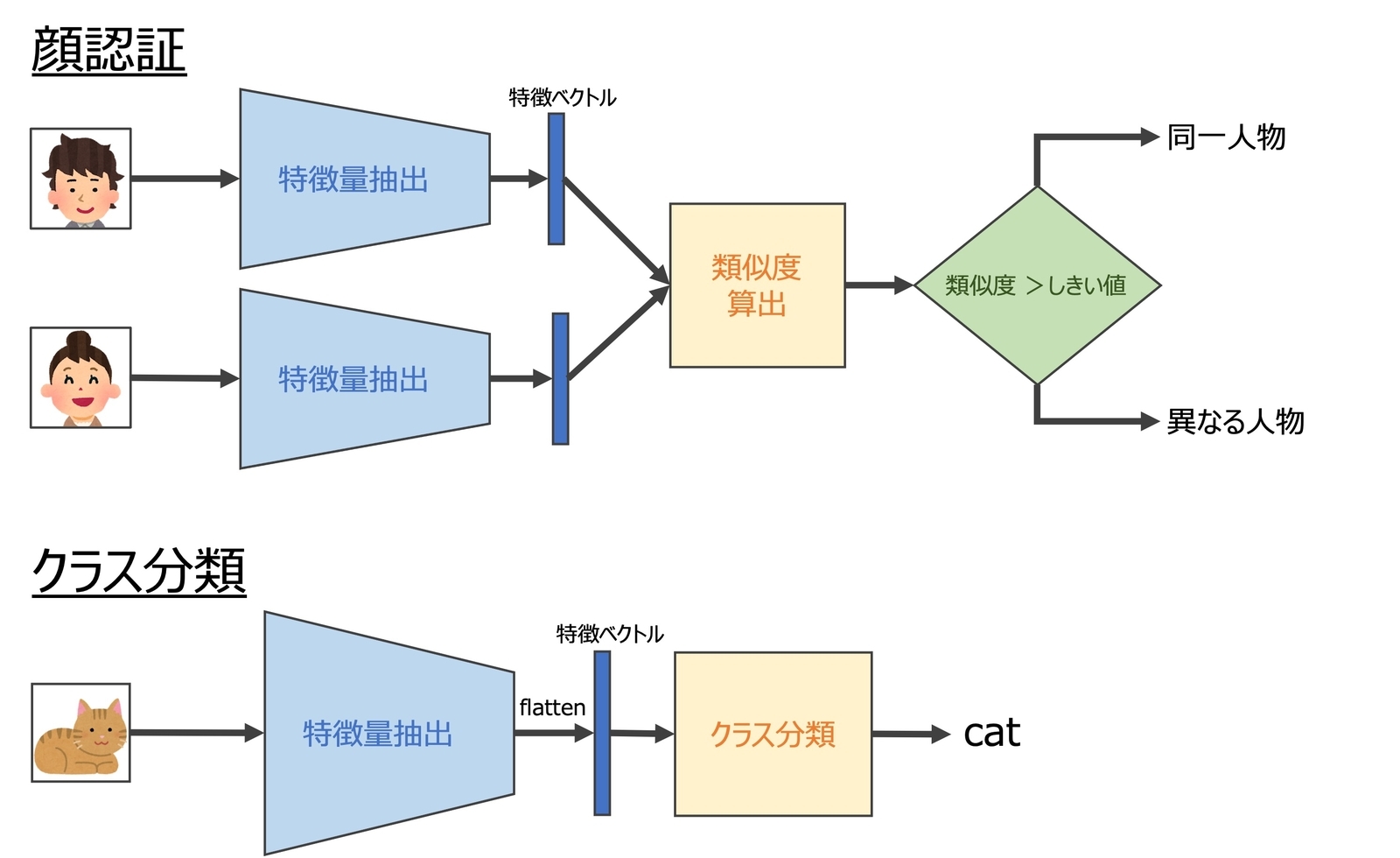
距離学習の主な目的は、入力画像を識別性の高い特徴量に変換する特徴量抽出器(図4-5の)を得ることです。得られた特徴量をどのように利用するかは、用途によって異なります。例えば、顔識別では、入力画像と参照画像から抽出した特徴量を比較し、同一人物の画像であるか異なる人物の画像であるかを検証します(図6)。分類タスクでは、得られた特徴量を分類器に入力し、どのクラスに属するかを判断します。一つの方法としては、特徴量と各クラスの中心位置との距離を比較し、コサイン類似度が最も高い(または距離が最も小さい)クラスを予測クラスに割り当てることです。
深層距離学習の利点と応用
- 定番の分類モデルとは異なり、識別性の高い特徴量を得ることができるため、極端に不均衡なデータセット(異常検知、医用画像診断など)や、Few-Shot learning(顔認識、手書き認識、音声認識など)や、Zero-Shot learning(訓練データに存在しないクラスを扱う必要があるタスク)などに対応できます。
- クラス数に応じてサイズが大きくなる分類用のFC層が不要になるため、クラス数が多いタスクではモデルサイズがより小さくなります。
まとめ
- 深層距離学習は、識別性の高い(discriminative)特徴量を得るためにディープニューラルネットワークを学習させる手法です。得られたモデルは特徴量抽出器として利用します。
- 不均衡データやFew-ShotとZero-Shot learningなどの課題でよく使われています。
- 学習手法は大きく、対照的アプローチとSoftmaxをベースにしたアプローチに分けられます。それらの代表的な手法としては、Triplet lossとArcFaceが挙げられます。
- 対照的アプローチの手法では、サンプルの組を入力データとし、正解ラベルはペアの種類(positive/negative)となります。一方、Softmaxをベースにしたアプローチでは、定番のクラス分類と同様に、入力と正解ラベルは入力画像とそのクラスラベルとなります。
- 対照的アプローチでは、損失関数の設計の他に、サンプル選択の設計も大事です。
- Softmaxをベースにしたアプローチでは、訓練時で特徴量抽出器と全クラスの中心位置に相当した重み
を同時で学習させたため、推論時でクラス分類をしたい場合はその重みを利用できます。(訓練データに存在しないクラスがある場合は対応不可)
- 本記事では画像データの分析で説明しましたが、入力データは画像に限られません。
おわりに
OPTiMでは、AIとIoT技術でビジネス課題・社会的課題を解決したい、チャレンジ精神・向上心を持っているエンジニアを積極的に募集してます。農業・医療・建設・産業分野などにおいてAIやIoTの活用で推進しているため、関心のある技術領域に挑戦するチャンスがあります。興味のある方は、こちらをご覧ください。 www.optim.co.jp
参考文献
- Wen, Y., Zhang, K., Li, Z., & Qiao, Y. (2016, October). A discriminative feature learning approach for deep face recognition. In European conference on computer vision (pp. 499-515). Springer, Cham.
- Cui, Y., Zhou, F., Lin, Y., & Belongie, S. (2016). Fine-grained categorization and dataset bootstrapping using deep metric learning with humans in the loop. In Proceedings of the IEEE conference on computer vision and pattern recognition (pp. 1153-1162).
- Kaya, M., & Bilge, H. Ş. (2019). Deep metric learning: A survey. Symmetry, 11(9), 1066.
- Hadsell, R., Chopra, S., & LeCun, Y. (2006, June). Dimensionality reduction by learning an invariant mapping. In 2006 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR'06) (Vol. 2, pp. 1735-1742). IEEE.
- Wang, J., Song, Y., Leung, T., Rosenberg, C., Wang, J., Philbin, J., ... & Wu, Y. (2014). Learning fine-grained image similarity with deep ranking. In Proceedings of the IEEE conference on computer vision and pattern recognition (pp. 1386-1393).
- Chen, T., Kornblith, S., Norouzi, M., & Hinton, G. (2020, November). A simple framework for contrastive learning of visual representations. In International conference on machine learning (pp. 1597-1607). PMLR.
- Deep Metric Learning: a (Long) Survey
- Wang, J., Zhou, F., Wen, S., Liu, X., & Lin, Y. (2017). Deep metric learning with angular loss. In Proceedings of the IEEE International Conference on Computer Vision (pp. 2593-2601).
- Wu, C. Y., Manmatha, R., Smola, A. J., & Krahenbuhl, P. (2017). Sampling matters in deep embedding learning. In Proceedings of the IEEE International Conference on Computer Vision (pp. 2840-2848).
- Duan, Y., Zheng, W., Lin, X., Lu, J., & Zhou, J. (2018). Deep adversarial metric learning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (pp. 2780-2789).
- Liu, W., Wen, Y., Yu, Z., Li, M., Raj, B., & Song, L. (2017). Sphereface: Deep hypersphere embedding for face recognition. In Proceedings of the IEEE conference on computer vision and pattern recognition (pp. 212-220).
- Wang, H., Wang, Y., Zhou, Z., Ji, X., Gong, D., Zhou, J., ... & Liu, W. (2018). Cosface: Large margin cosine loss for deep face recognition. In Proceedings of the IEEE conference on computer vision and pattern recognition (pp. 5265-5274).
- Deng, J., Guo, J., Xue, N., & Zafeiriou, S. (2019). Arcface: Additive angular margin loss for deep face recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (pp. 4690-4699).
- Zhang, X., Zhao, R., Qiao, Y., Wang, X., & Li, H. (2019). Adacos: Adaptively scaling cosine logits for effectively learning deep face representations. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (pp. 10823-10832).
- Sun, Y., Cheng, C., Zhang, Y., Zhang, C., Zheng, L., Wang, Z., & Wei, Y. (2020). Circle loss: A unified perspective of pair similarity optimization. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (pp. 6398-6407).
- DENG, Jiankang, et al. Sub-center arcface: Boosting face recognition by large-scale noisy web faces. In: European Conference on Computer Vision. Springer, Cham, 2020. p. 741-757.
- Ha, Q., Liu, B., Liu, F., & Liao, P. (2020). Google Landmark Recognition 2020 Competition Third Place Solution. arXiv preprint arXiv:2010.05350.
- Jiao, J., Liu, W., Mo, Y., Jiao, J., Deng, Z., & Chen, X. (2021). Dyn-arcFace: dynamic additive angular margin loss for deep face recognition. Multimedia Tools and Applications, 1-16.
- Meng, Q., Zhao, S., Huang, Z., & Zhou, F. (2021). Magface: A universal representation for face recognition and quality assessment. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (pp. 14225-14234).
- Schroff, F., Kalenichenko, D., & Philbin, J. (2015). Facenet: A unified embedding for face recognition and clustering. In Proceedings of the IEEE conference on computer vision and pattern recognition (pp. 815-823).