自己紹介
初めまして。21新卒で入社いたしました、技術統括本部SREユニットの岡田です。 大学院在籍時にPythonを使用した機械学習でのデータ解析を行っていましたが、入社まで運用はもちろん開発も未経験でした。社内でのIT人財教育プログラム(IT研修)ののち、サービスを横串でサポートするSREユニットにて勤務しております。配属直後、サービス運用に必要なツールを実際に使用してアプリケーションをデプロイした話を今回はお伝えしていきます。
はじめに
入社してから6月末までは、社内のIT研修を受けておりました。研修の後半では、簡単なチャットアプリをチームで開発していました。チームメンバーと日々、四苦八苦しながら取り組んだことが既に懐かしく思えます。 6月末にSREユニットに配属されてからは、まずこのチームで頻繁に触れるAWSやKubernetesの理解を深める必要がありました。そこで、研修で作成したチャットアプリをEKSにデプロイすることで経験を積みました。さらに、サービスを運用する上ではどんな考え方が重要であり、そのためにどんなツールがあるのかについてもこの記事にまとめました。
やったこと
運用の観点から、同じ構成を素早く構築できるような再利用性を高くした構成管理ができることを心がけました。 大きく分けて以下3つをSREの先輩方に教わりながら行いました。
IT研修で作成したチャットアプリは、Webサーバーをlocalhostに構築し、コンテナの管理にはDocker Composeを用いました。DBとしてPostgreSQLを用いています。フロントエンドにはVue.jsを、APIにはGoを用いました。この構成を以下の流れで変更しました。その変遷をぜひご覧ください!

EKSへのデプロイ
研修ではDocker Composeを用いて複数のコンテナ管理を行なっていました。変更があればそれぞれのコンテナの設定ファイルを修正・更新したり、フロントエンドやバックエンドのコードを修正した後、コンテナを手作業で立ち上げ直していました。改めて考えると非常に手間がかかっています。今回作成したチャットアプリは立ち上げるコンテナ数が3つと少ないため大きな問題ではありませんでしたが、サービス単位で考えるととてもやっていけません。近年では、どれか一つのコンテナが障害になった場合に止まらないようにする(信頼性を高める)、メンテナンス作業があっても稼働が停止しない(可用性を高める)、キャパシティを拡大可能にする(スケーラブルにする)ために、Kubernetesが広く使われています。今回はAWSでアプリケーションの環境を作成するため、Amazon Elastic Kubernetes Service(EKS)を使用しました。
EKSを使用する目的、理由
- コンテナの一括管理を効率よく行うため。
- 一つのサーバーで動かすのであれば問題はないが、複数サーバで管理したり、扱うコンテナが増えたときにとても手作業では対応しきれない。
- 他のAWSサービスとの統合が簡単。
- ALB、ECR、RDSなど、AWSのネットワークのサービスやセキュリティのサービスとすぐに統合ができる。
設定した内容
ALBからTraefikへのルーティングが設定されたクラスターを使用しました。ECRは事前に用意していただきました。
- Manifestの作成
- 以下のManifestを作成し、EKSへ
kubectl applyしました。- フロントエンド、バックエンドのDeployment
- フロントエンド、バックエンドのService
- フロントエンドのIngress
- DBのマイグレーションを行うJob
- また、
docker-compose.ymlや.envファイルで指定していた環境変数もここで設定しました。
- 以下のManifestを作成し、EKSへ
- Dockerfileの作成、Amazon Elastic Container Registry(ECR)へ追加
- 以下のDockerfileを開発環境時から作り直しました。例えば、開発環境時にはコンテナ起動の際に
yarn installとyarn serveを行っていませんでした。イメージサイズを節約したり、起動サーバの数をなるべく少なくしてアプリ開発の効率を高めることが目的でしたが、これは運用環境には適していません。そこで、コンテナ起動時の実行コマンドなどを変更した新しいDockerfileをdocker build、作成したイメージをECRへdocker pushしました。- フロントエンドコンテナ
- 起動時に
yarn serveするようにしました。(本番環境では非推奨)
- 起動時に
- バックエンドコンテナ
- 起動時に実行するようにしました。
- DBマイグレーションコンテナ
- フロントエンドコンテナ
- 以下のDockerfileを開発環境時から作り直しました。例えば、開発環境時にはコンテナ起動の際に
構成の変化
EKSへデプロイすることで、構成が以下のように変わりました。併せて、今回新たに作成したものも記載しています。各コンテナをEKSで管理するようになったことで、障害が発生しても手作業で直す必要がなくなりました。この数ではあまり恩恵を受けませんが...。

TerraformでのRDS構築
アプリケーションの構成をEKS、Docker imageをECRで管理することで、障害に強くスケーラブルなアプリケーション運用が可能になりました。このように、今回はAWS上でのアプリケーション管理を行うのでDBもAmazon Relational Database Service(RDS)にして管理することにしました。RDSを利用することで、可用性とスケーラビリティが高いDBを構築できます。PodでのDB運用時にはPod再作成時にデータを消失する構成になっていましたが、RDSで運用することでデータの冗長化・バックアップなど永続化に関する責任をAWSに任せることができます。しかしながら、他の環境でも同じようなRDSを立ち上げ可能にするためにはその構成を引き継がなければなりません。また、今回使ったインスタンスタイプや接続時の情報は変更可能にしておきたいところです。そこで、宣言的な*IaCツールの一つであるTerraformを用いて構成管理を行いました。
* Infrastructure as Code(IaC)。 インフラの構成をコード化して管理すること。構成管理手段の1つ。
Terraformを使用する目的
- 同じ構成を素早く構築可能な、再利用性が高い(ヒューマンエラーを削減した)構成管理を行うため。
- バージョンの管理を行い、コードの変更履歴を追跡可能にしたり、データセンターが災害などで落ちてしまっても別のデータセンターで素早く復旧可能になる。
- 環境差分だけを抽出して.tfvarsファイルで管理することで、同じ構成の環境を簡単に構築できる。
設定した内容
非常に低コストであることとその速度に加え、耐久性が他のサービスよりも高いことからDBとしてAmazon Aurora PostgreSQLを使用しました。インスタンスから分離して3つのAvailability Zoneでストレージが管理されるため、いずれかのストレージがデータを消失しても修復が可能になっています。インスタンスクラスには、aurora-postgresql 12.4で起動できるもののうち最安値でありパフォーマンスも十分なdb.t3.mediumを設定しました。
- Aurora PostgreSQLを管理するうえでの環境変数をterraform.tfvarsに書き出しました。
- ルートモジュールから、今回のチャットアプリ用Aurora PostgreSQLのサブモジュールを参照するような構成に変更しました。
terraform applyで変更内容を反映しました。
構成の変化
TerraformでRDSを構築することで、構成が以下のように変わりました。コンテナで立ち上げていたDBが、RDSに替わっています。これで、データの永続化に関する責任をAWSに任せるだけでなく、DBの立ち上げ・構成管理の手順をTerraformで行うことで属人性を低減しつつ再利用性を高くすることができました。

アプリケーションのHelm化
設定したい環境変数は、Manifestに記述することで各Resourceが参照できるようにしていました。しかし、変更がある際kubectl apply前にどのマニフェストで何の設定をしたかを一々辿るのは面倒ですし、その説明をREADMEに書くのも煩雑になりそうです。そこで、KubernetesのパッケージマネージャであるHelmを用いてアプリケーションのパッケージマネジメントを行いました。
Helmを使用する目的
- デプロイしたアプリケーションの管理を簡単にするため。
- 内容の更新(バージョンのアップデートなど)を、Chartと呼ばれる設定ファイルで管理する。パラメータを切り出したvalues.yamlとKubernetes ManifestをHelm Chartとしてパッケージングすることで、アプリケーション構成の再利用が可能になる。
設定した内容
helm createでHelmの構成を作成し、内部のtemplatesディレクトリに作成したManifestsを追加しました。- values.yamlに、デフォルトパラメータを記述しました。この際、新たに使用するDocker imageのバージョンも管理できるようにしました。
- templatesに追加したManifestsがvalues.yamlを参照できるように更新しました。
helm installでEKSへアプリケーションをデプロイしました。
これで、values.yamlを見ればパラメータをを確認でき、変更がある場合にはvalues.yamlを更新した上でのデプロイが可能になりました。
構成の変化
作成したManifestをHelm Chartにパッケージングした、最終的な構成が以下になります。

結果、学び
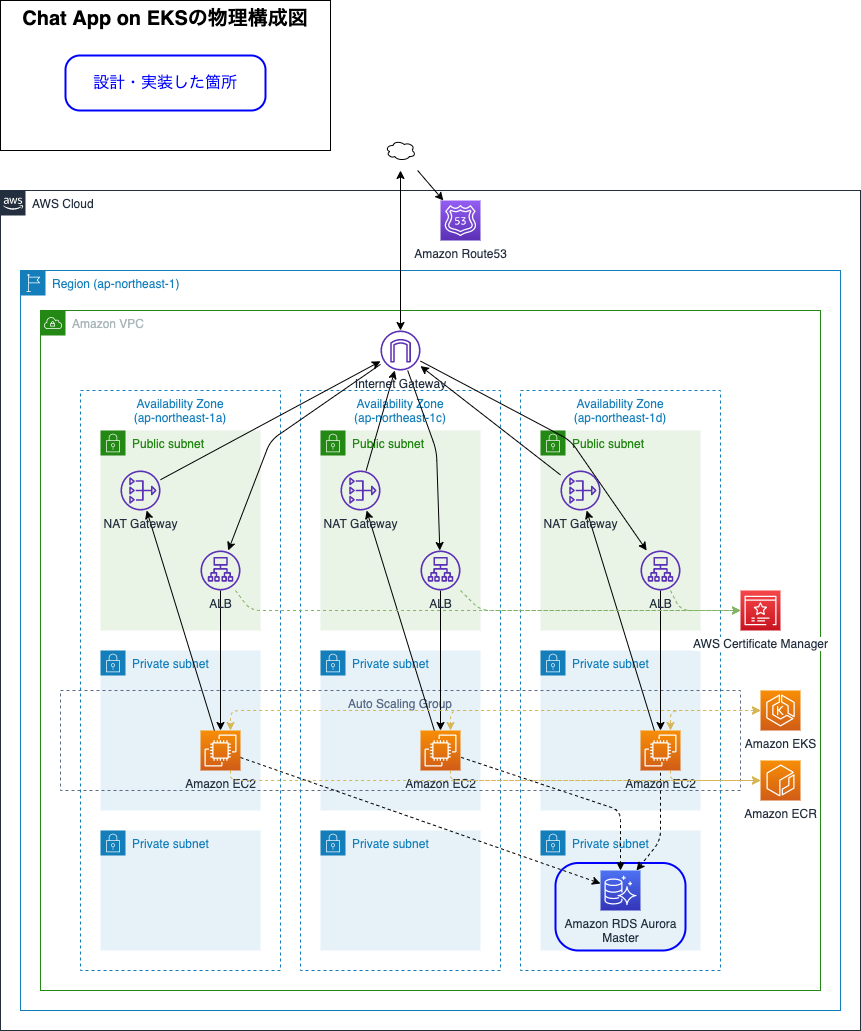
今回作成したチャットアプリの物理構成図は以下のようになっています。RDSの実装はお金がかかるためシングルAZで行いましたが、設計上はマルチAZとしました。EKSへのデプロイ、TerraformでのRDS構築、アプリケーションのHelm化の3ステップで、研修時に作成したチャットアプリは信頼性・可用性・スケーラビリティの高いサービスとなりました。実際のチャット画面も併せて示しています。
 |
 |
RDSに変更を加えたい場合はterraform.tfvarsファイルを、EKSの設定に変更を加えたい場合にはvalues.yamlを参考にしながらパラメータを書き換えることで、チャットアプリの環境構築を行うことができます。また、チャットアプリ自体の更新を行なった後は、ECRにDocker imageをpushしてからそれを参照するように上述のファイルを更新することで、アップデートを行えます。
運用に必要な各種ツールを使ってみての学び
- 可能な限りヒューマンエラーを取り除くこと
- IT研修の際には、環境構築に1週間近く費やしたことが記憶に新しいです。設定に変更があった場合にも、いろんなファイルを行ったり来たりして直し、バグがあれば質問し、サポーターの皆さんには助けて頂きながらも多大なコストをかけていたなあと思います...。最も難関であった環境構築をコマンド1つで再現できるように設定することは、多くの手間を省けることを、様々なツールを使用して痛感しました。また、環境差分を一つのファイルに切り出すなど、変更する際には必要最低限のファイルを確認すれば済むようにすることで、管理を簡易にすることの重要さも体感しました。IaCの考えを忘れず、様々なツールの理解・使用の際にも応用していきたいと思います。
- 面倒な管理をマネージドサービスに任せること
- 人間がとても捌ききれない量の管理をAWSが提供しているマネージドサービスなどを利用することの便利さも今回学んだことの1つです。全てを自社サーバーなどでやりくりするのは限界があること、フルマネージドサービスが多くある現在はそれらをどう活用するかを考えることが肝要であることを学びました。しかしながら、これらの使用には安くないコストがかかるため、何をどう選んでいくか、本当にそれで十分なのかを吟味することが重要であると感じました。現在SREでも監視やコストの可視化を行なっていますが、実際にどう繋がっていくかの一部を自分で体験することができました。
- Kubernetesの奥の深さ、AWSの凄さ
- 使用してみたことで、一度デプロイが完了すれば後の管理を全て行ってくれるというのは非常に便利であると実感しました。しかしながら、どう管理して欲しいかを最初に考えることは非常に難しかったです。今回は基本的な設定しか行っていませんが、何をコードとして切り出せば良いのかは、実際に開発・運用の現場を知らないと設定できないと思いました。また当たり前ですが、ネットワークの知識がないとAWSの設定で何が行われているかを全く理解できませんでした。経験値も積みつつ、この観点の知識を頭に入れていきたいです。
おわりに
SREの先輩方にたくさんのサポートをいただき、今回多くのことを経験・学ぶことができました。この場を借りて、改めて御礼申し上げます。 IT研修の成果物を運用の観点から改良してみたわけですが、新しい知識が大量に入ってくる中で理解が追いつかないことにもどかしさも感じました。その中で、同じアプリケーションを扱っていても開発・運用では着目する観点が大きく異なること、運用側で意識すべきことを実際にアプリをデプロイすることで経験することができました。IaCの考え方の重要さ、各種ツールの便利さと共通点など、日々いろんなことを吸収しつつ、SREとしてサービスの運用に貢献できるよう頑張ります。 最後まで読んでいただきありがとうございました!
以下のように、私のようなプログラミング開発・運用未経験でも入社後にIT研修にてプログラミングの基礎を経験できます。
OPTiMでは随時、エンジニアを募集しております。出身学部・専攻に関係なく、自分の興味があることに挑める職場になっております!