はじめに
こんにちは、プラットフォーム技術戦略室SREチームの山田です。
今回はOPTiM Cloud IoT OSを運用する上で問題になってきたインフラコスト肥大化に対する最適化の対応の一つとして
開発/検証環境を利用時間外に停止し、インフラコストを削減した内容について記載いたします。
AWSコスト整理
コスト分析していく中で、全体のおよそ78%をAWSにコストがかかっていたため、AWSのコスト最適化に注力することにしました。
AWSのコスト整理を行った所、例として以下のようになりました。
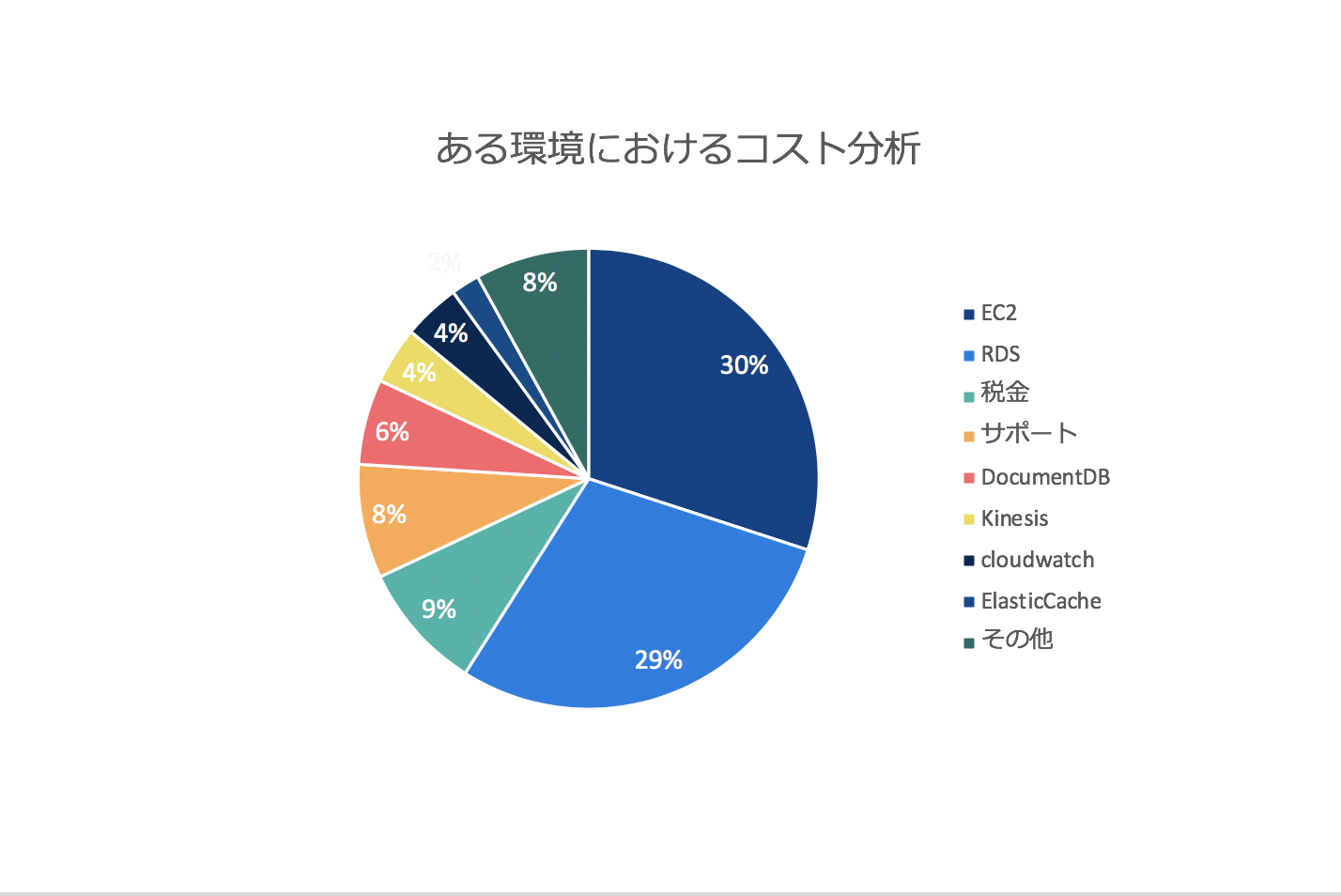
全体的にRDS/EC2のコスト比率が高いので、EC2/RDSの費用削減に注力することにしました。
削減方法としては、当初RIやSpotインスタンスの利用についても検討しましたが、検証/開発環境に関しては以下の観点より、停止運用を採用することにしました。
- 業務時間外に停止しても問題がない
- RIやSpotインスタンスの利用と比較してもコスト削減率が停止運用の方が高い
停止運用の実施
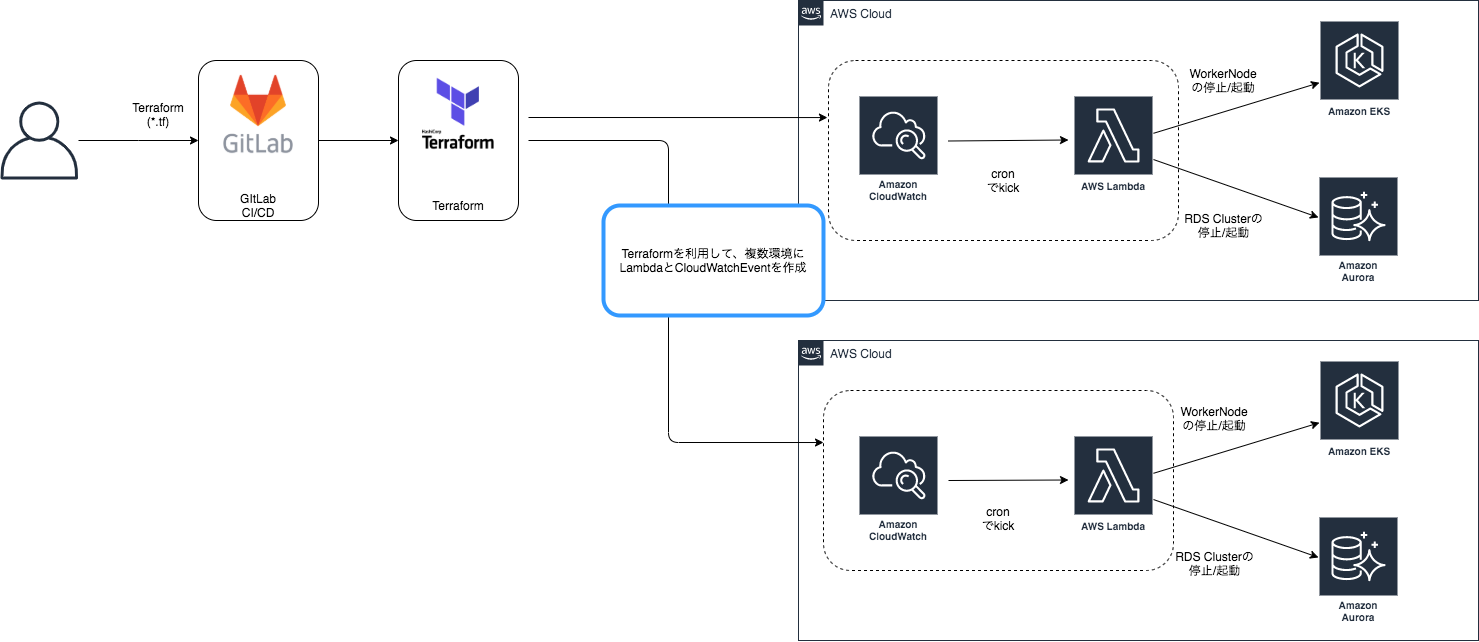
OPTiM Cloud IoT OSではメインにEKSを利用し、DB部分ではAuroraを利用しています。
今回の停止運用については業務時間外後の特定の時刻になった際にAuroraはClusterを停止し、EKSについてはWorker NodeをAuto Scaling Groupの値を0に設定することで停止運用を実現させています。
こちらの実装については、Lambdaと CloudWatch 利用し、構成管理をTerraform + GitLab CI/CDで行っています。
下記の図は停止運用実装部分の簡易図になります。
今回、LambdaではpythonとBoto3を利用して実装しています。 boto3.amazonaws.com
- RDSの起動処理
import boto3 client = boto3.client('rds') def lambda_handler(event, context): for DBClusterIdentifier in describe_db_clusters() : response = client.start_db_cluster(DBClusterIdentifier = DBClusterIdentifier) def describe_db_clusters(): clusters = [] response = client.describe_db_clusters() for DBCluster in response['DBClusters']: clusters.append(DBCluster['DBClusterIdentifier']) return clusters
- RDSの停止処理
import boto3 client = boto3.client('rds') def lambda_handler(event, context): for DBClusterIdentifier in describe_db_clusters() : response = client.stop_db_cluster(DBClusterIdentifier = DBClusterIdentifier) def describe_db_clusters(): clusters = [] response = client.describe_db_clusters() for DBCluster in response['DBClusters']: clusters.append(DBCluster['DBClusterIdentifier']) return clusters
- EKS Worker NodeのAuto Scaling Group変更処理
import boto3 autoscaling = boto3.client("autoscaling") def lambda_handler(event, context): asg_name = event["AutoScalingGroupName"] max_size = event["MaxSize"] min_size = event["MinSize"] desired_capacity = event["DesiredCapacity"] for i in range(len(asg_name)): autoscaling.update_auto_scaling_group( AutoScalingGroupName=asg_name[i], MinSize=min_size[i], MaxSize=max_size[i], DesiredCapacity=desired_capacity[i] )
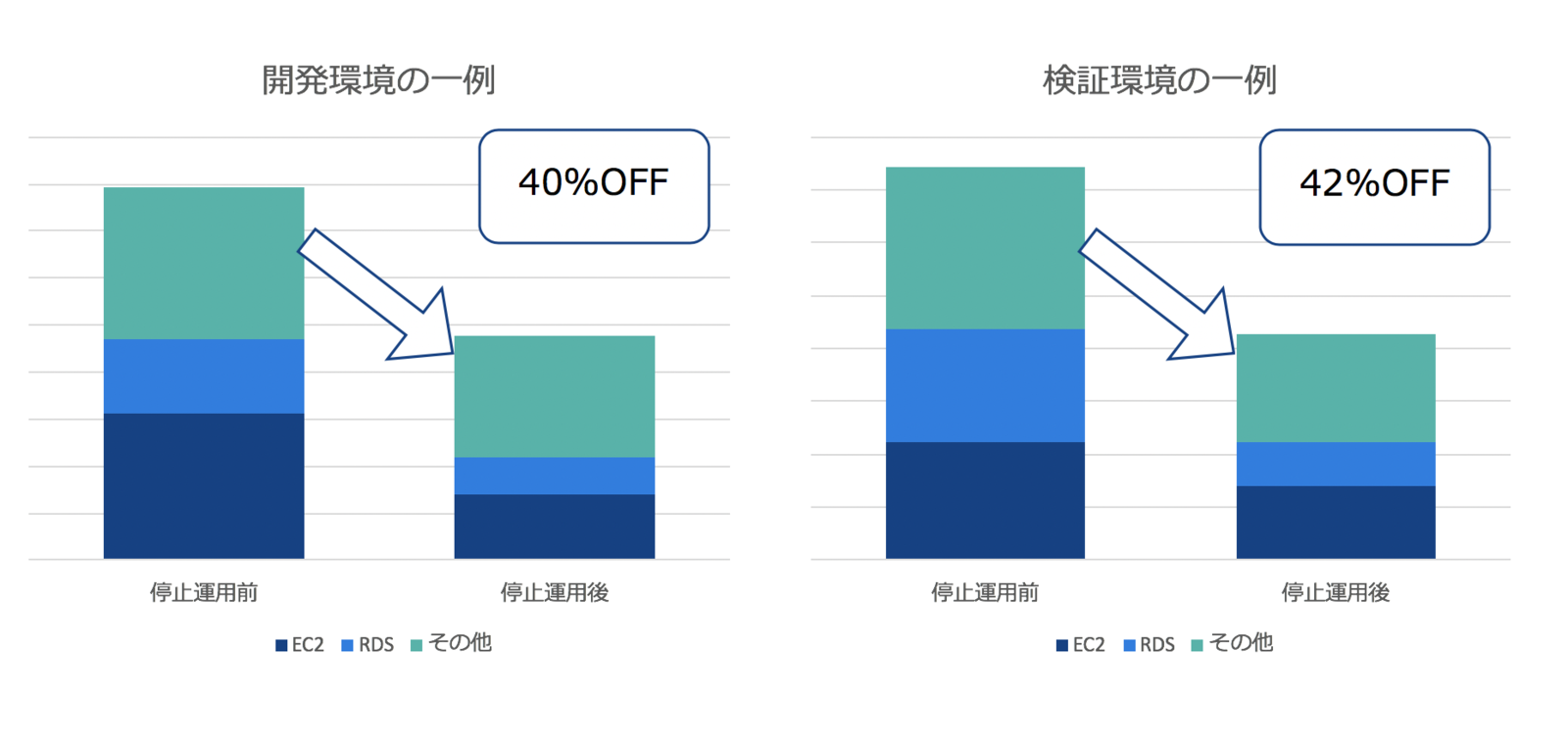
停止運用の成果
停止運用を実施したことで、各開発/検証環境毎におよそ30~40%程のコスト削減ができました。
停止時間に関して平日は12時間程停止状態にしており、土日に関しては終日停止にしています。
また、モニタリングツールとして利用しているDatadogのコストについても削減することができました。
問題点/改善点
- Podが特定のNodeに偏る
WokerNodeの起動タイミングに多少のズレが発生するため、先に起動したNodeにPodが集中していました。
そのため、deschedulerの導入を別途検討しています。
github.com - Podの偏りにより、起動できないPodが発生
DemonSetや特定のNodeのみでしか起動できないPodが、Pod起動上限値に引っかかって起動できなくなっていました。
問題解消のために、PriorityClassの見直しを実施しています。 - CronJobが連休明けに処理され続け、週明けにJobがパンクしていた
EKSのMasterNodeを停止しているわけではないため、CronJobに関してはスケジュールされていたことが原因でした。
特に検証のためにCronJobの実行間隔が短かったため、連休明けのNodeの起動とともにスケジュールされていたJobが一斉にキックされ、全NodeがPodの上限値に達していました。
問題として、CronJobの設定がほぼデフォルトのままだったため、CronJob実行時間を変更してもらう、startingDeadlineSecondsやconcurrencyPolicyを設定してもらうことで対応しています。 - Worker Node停止時にDrain処理が行われていない
諸事情でManaged Worker Nodeを利用していなかったため、KubernetesのDrain処理が行われずインスタンスをシャットダウンしてしまっていました。
現在、当事象への対応のため、下記の導入を検討しています。 github.com
終わりに
今回の対応で肥大化していたコストに対して、一定の効果が見られました。
また、簡易的な障害発生と似たような状態になったため、今まで検知できていなかった課題点が見つかったことは副次的効果として良かったです。
今後は、上記の課題に対して改善活動を進めていくと共に、別途コスト最適化活動を進めて行きたいと思います。
オプティムでは一緒に働く仲間を募集しています。
OPTiM Cloud IoT OS、SREに興味があると言う方は是非一度興味がある方は是非弊社採用ページをご確認してみてください。
www.optim.co.jp