はじめまして。プラットフォーム事業本部の栗原です。 業務では、主にCloud IoT OS チームにてSRE活動を行っています。
今回は、Cloud IoT OS(以下CIOSと記載します)で利用しているMongoDBクラスタの構築と運用についてお話をします。
構築に至った経緯
もともとは Azure CosmosDB の MongoDB APIを用いていたのですが、 CosmosDBの一部仕様がCIOSでのユースケースと合っていないという課題がありました。 いくつか存在したのですが、大きくは以下です。
- パーティション
- CosmosDBにはパーティションと呼ばれる仕様があります。これは、ざっくりいいますと
- パーティションと呼ばれる1つ10GBの論理ボリュームがあり、データは複数のパーティションに分割して書き込まれる
- どのパーティションにデータを書き込むかは、パーティションキーと呼ばれる値を用いて設定する
- 書き込みデータ中のどの値をパーティションキーとして利用するかは予め決めておく
- スケールはパーティション単位で行われる
- CosmosDBにはパーティションと呼ばれる仕様があります。これは、ざっくりいいますと
というものです。
上記仕様自体は問題ないのですが、それに関連した以下挙動が問題となりました。
- cursor.sort実施時に、データがパーティションをまたがっていると期待と異なる結果が返却される
- AggregationPipelineを用いたsortをつかえば期待通りの結果が返却されるが、集計対象データの全量が40MBを超えるとエラーとなってしまう
これらを回避しつつ機能を実現するためにデータ構造を見直す案も検討されましたが、 "MongoDBに置き換えたら問題が解決するのか"という点を確認してみよう、ということで構築計画がスタートしました。
(余談ですが、CosmosDBのMongoAPIとの区別のため、社内では"生Mongo"と呼ばれていました。)
自前運用を行うにあたり考慮すべき点
当たり前の話ではあるのですが、マネージド型データベースサービスだとすべてサービス側が行ってくれていたことを自前で行う必要があります。
ざっくりとは以下です。
- スケール設計
- 監視設計
- 障害となりうる点の把握
- 構成管理
- etc...
CIOS SRE チームでは"本番運用に耐えうるか"という観点でのシステムレビュー(Production Ready活動)を進めています。 この点については、また機会があればお話させていただければと思います。
構成について
MongoDBは単独のプロセスでも動作しますが、
- プロセスがダウンすると利用できなくなる
- 大量アクセスに耐えるためにはプロセスが動作するマシンをスケールアップするしかない
- スケールアップには限界がある
等の問題があり、大規模利用には耐えません。
でも大丈夫。MongoDBはクラスタを組むことで上記問題に対応できます。
以下はMongoDBクラスタの論理構成例となります。
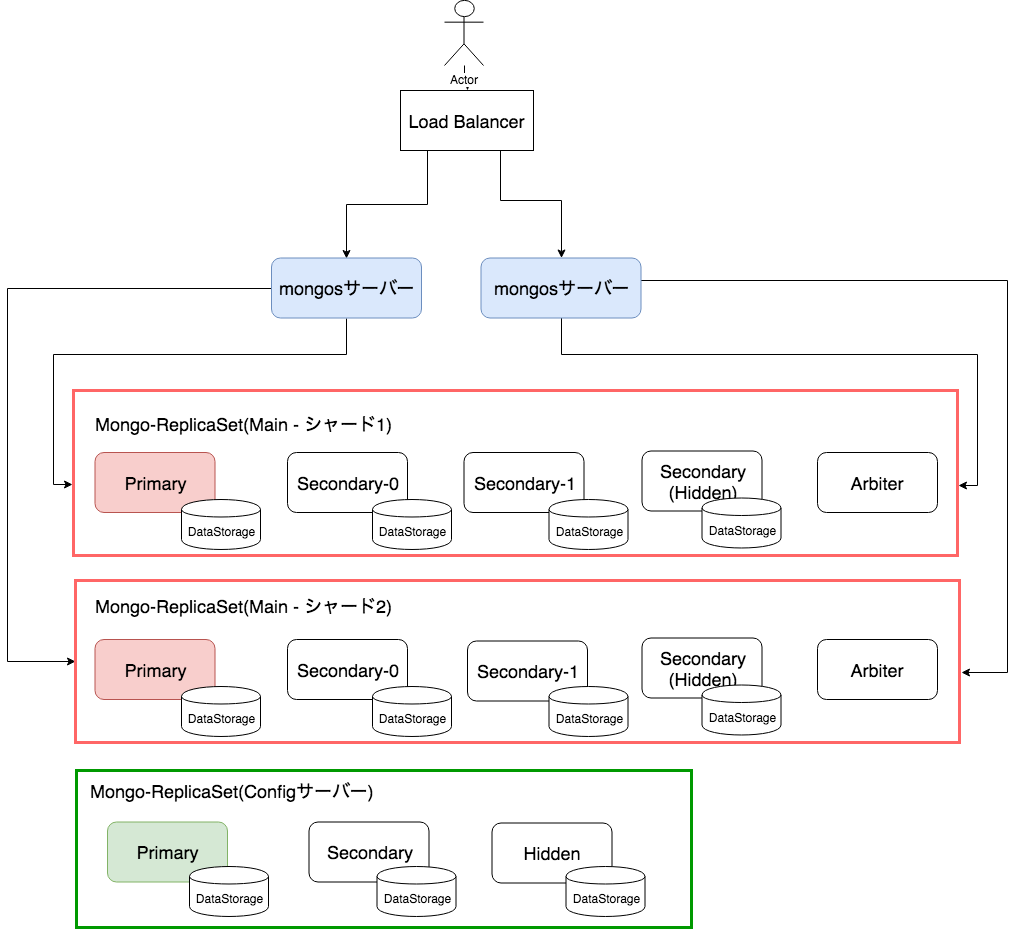
各要素について以下に記載します。
ReplicaSet
複数のMongoDBプロセスで同じデータを保持することにより、データの冗長性やDBの可用性を高める事ができる仕組みです。
ReplicaSetに所属するMongoDBプロセスはそれぞれ役割をもち、協調動作することで機能を提供します。
いずれかのMongoDBプロセスがダウンしたりデータが壊れてしまった場合には、他MongoDBプロセスがその役割を肩代わりすることでDBが利用できなくなってしまう状況を防ぎます。
役割には以下があります。
- primary
- 主役です。データの書き込み処理、呼び出し側設定によっては読み込み処理も担います。
- ReplicaSetの中で常に1つだけが存在します。
- secondary
- primaryのデータコピーを保持します。また、呼び出し側設定によっては読み込み処理も担います。
- primaryがダウンしてしまった場合、残ったsecondaryのいずれかがprimaryに自動的に昇格します。この仕組みによりDBが処理を継続することができます。
- secondaryが複数いた場合は、残ったMongoDBサーバ内で選挙をし誰がprimaryになるかを決定します。
- hidden
- secondaryの一種です。primaryのデータコピーを保持しますが、読み込み処理は行いません。また、primaryに昇格することもありません。
- 主にデータのバックアップに利用されます。
- arbiter
- データの保持も読み込みも書き込みもおこないません。
- "どのsecondaryがprimaryになるか"の選挙を行う際、メンバの数が偶数だとだれがprimaryとなるか決められない場合が存在します。そういった状況にならないよう、メンバを奇数とするための数合わせとして用いられます。
シャーディング
データを複数のReplicaSetに分散して読み書きすることにより、読み書き負荷を分散する仕組みです。
本機能により、大量のリクエストをさばく必要が出てきたときにもレプリカセットを増やすことにより対応が可能です。 (シャーディングにおいて、各ReplicaSetは"シャード"と呼ばれます)
"読み書きをどのシャードに対して行うか"は、シャードキーと呼ばれるデータに対する識別子によって決定されます。
データ中の何をシャードキーとして利用するかは自由ですが、値に偏りが生じるようなものを設定してしまった場合、 "特定シャードにばかり読み書きされてしまい負荷分散されない"ことが起こりうるため注意が必要です。
configサーバー
シャーディングに関する情報を保持します。
本サーバーが止まってしまうとシャーディングの機能が利用できなくなってしまうため、ReplicaSetとすることで可用性を高めておく必要があります。
mongosサーバー(と Load Blancer)
外部からのリクエストを受けつけ、シャードキーを元にどのシャードに対してアクセスすべきかを判断、ルーティングします。
mongosサーバーが1台だけの場合、止まってしまった場合にクラスタ自体にアクセスできなくなってしまう、また、高負荷の場合ボトルネックとなってしまうため、通常複数台立ち上げ前段にLoadBlancerを噛ますことで冗長化&負荷分散を行います。 (LoadBlancer自体の負荷対策と冗長化については別途行う必要がありますが、MongoDBの話からずれるため割愛します。)
読み書きの流れについて
- 書き込み
- mongosサーバにより"どのシャードに書き込むべきか"を判断されたのち、対象シャードのprimaryに対して書き込みを行うようルーティングされます。 "どのシャードに書き込むべきか"はデータ中のシャードキーと、configサーバがもつシャーディング情報により判断されます。
- 読み込み
- どのシャードから読み込むべきかによってルーティングされる点は書き込みと同じですが、読み込み側の設定によってアクセスするReplicaSetのメンバが異なります。この設定を"ReadPreference"と呼び、以下の値が設定可能です。
- primary
- primaryからのみ読み込みます。
- primaryPreferred
- 可能な限りprimaryから読み込みます。primaryが利用できない場合はsecondaryから読み込みを行います。
- secondary
- secondaryから読み込みを行います。
- secondaryPreferred
- できるかぎりsecondaryから読み込みを行いますが、secondaryが利用できない場合はprimaryから読み込みを行います。
- nearest
- ネットワーク通信の待ち時間が最小となるメンバから読み込みを行います
- primary
- どのシャードから読み込むべきかによってルーティングされる点は書き込みと同じですが、読み込み側の設定によってアクセスするReplicaSetのメンバが異なります。この設定を"ReadPreference"と呼び、以下の値が設定可能です。
- なぜこういった設定が可能としているかについては長くなってしまうため割愛しますが、気になる方は以下公式ドキュメントを参照してみてください。
構築について
物理構成の検討
ここからは、物理構成(実際のVM上にMongeDBプロセスをどのように配置するか)のお話となります。
以下選択肢がありました。
- OS上で直接MongoDBプロセスを動作させる
- Kubernetesクラスタ上に構築
- 各MongoDBプロセスはpodとして動作させる
直接MongoDBプロセスを動作させた場合、以下のような構築コストと構成管理に関する懸念事項がありました。
- 1VM 1プロセスとした場合、VMの台数がかさむ
- 1VM上にて複数プロセスを動作させた場合、利用ポート番号の管理や通信制御が煩雑となる
逆に、Kubernetesを利用した場合の懸念としてなにか問題が起きたときの切り分けポイントが増えてしまう点が存在します。 たとえば、ReplicaSetのあるメンバとの疎通ができなくなったとして、 各プロセスの状態やVM間ネットワーク疎通だけでなく、Kubernetesの通信周りの機能(kube-proxyやkube-dns等)不備によって問題が起きている可能性も考慮に入れる必要があります。
検討の結果、デメリットはありつつも以下が容易であるという理由から2.のKubenetes クラスタを用いた構成としました。
- 構成管理
- 各pod(MongoDBプロセス)の死活監視とオートヒーリング
- スケールアウト
- データストレージの管理
- バッチジョブの実行と管理
- MongoDBプロセス間の通信設定
- スモールスタート(少数VMでのクラスタ構築)
Kubernetes利用のデメリットはサービスメッシュの導入により改善が見込みるものですが、本構成には導入できていないため、今後の改善ポイントとなります。
(なお、1., 2. の方法ともにそれぞれ構成管理ツール(OpsManager, CloudManager, MongoDB Operator, MongoDB atlas)が存在するのですが、費用面で折り合いがつかない、要件を満たさない、ベンダーロックインを避けたい等の理由で自前で構成管理をしています)
物理構成
Kubernetesの利用を選択した結果、実際に構築したクラスタは以下の様になりました。
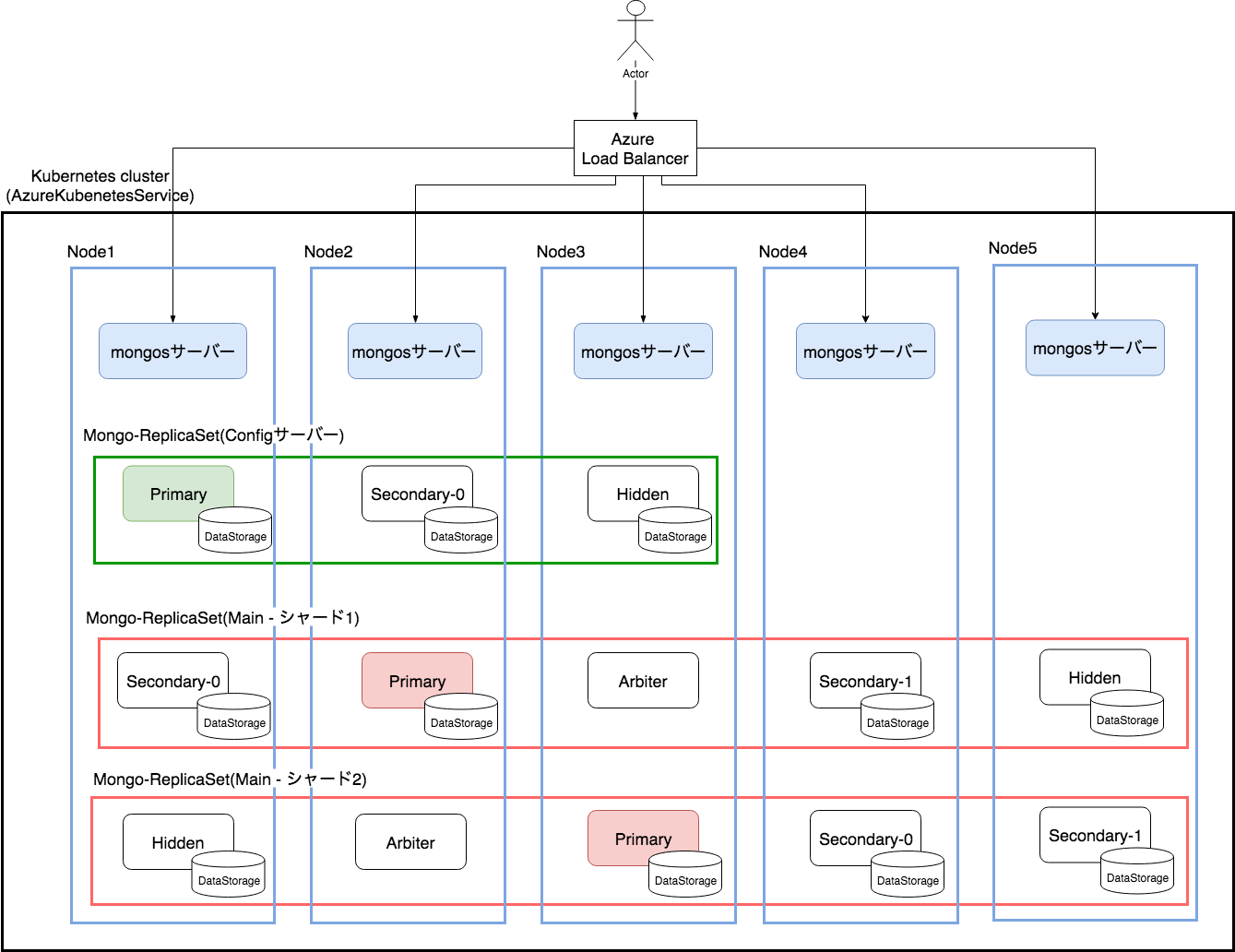
- マネージドなKubernetesサービスとして、AKS(AzureKubernetesService)を利用し、その上に構築を行っています。
- LoadBalancerはAzureLoadBalancerをもちい、バックエンドサーバとして各nodeのmongsサーバーを登録しています。
- DataStorageはDynamic Provisioning を用いて作成することで、必要になったタイミングでAzureのManagedDiskが動的に生成&マウントされるようにしています。
podの配置では以下点を気にしてしています。
- primaryが同一ノードに偏らないようにする
- ReplicaSetのメンバが同一ノードに偏らないようにする
これにより、いずれかのノードがダウンしてもReplicaSetが機能停止しないようにしています。 また、mongosサーバーは各ノードに一つづつ配置しこちらもノードのダウンに耐えられるようにしています。
実際には、本構成をベースに必要に応じてシャードの数やレプリカのメンバ数、node(VM)数を調整しています。
スケールアウト
高負荷への対策としてスケールアウトを行う場合はVMの追加+シャードの追加を考えます。 VMはそのままでシャードのみ追加することも可能です。その場合、ディスクI/Oの負荷は分散されますが、
- primaryの数 > VMの台数 となってしまった場合、複数のprimaryが同一のVM上にのってしまうこととなりそのVMがダウンした際の影響が大きくなる
- cpu、メモリ、ネットワーク帯域等、VMのリソースがボトルネックとなる場合がある
ため、VMの追加と合わせて考えます。
オートスケールは現状未対応であるため、利用状況を監視しつつ手動でスケールを実施する運用となります。この点も今後の改善事項となります。
運用
監視
監視は主にDatadogを用いて実現しています。
以下のようなメトリクスを収集し、利用状況の把握や異常時のアラート通知に用いています。
- CPU利用率等、VMレイヤのメトリクス
- podの状況等、Kubernetesレイヤのメトリクス
- MongoDB特有のメトリクス
- DataDogのMongoDBインテグレーションを用いておこなっています。
バックアップ
デイリーでのフルバックアップと、定周期での差分バックアップを行っています。
バックアップをとっている最中に内容が変わってしまうと困るため、書き込み(secondaryの場合はprimaryからのデータコピー)を止めた状態のデータに対してバックアップを実行する必要があります。
が、primaryの書き込みを止めてしまうと利用者が書き込みを行えなくなってしまします。
かといって、secondaryへの書き込み(primaryからのデータコピー)を止めてしまうと、ReadPreferenceにsecondary等が指定されていた場合、利用者が古いデータを読み込んでしまいます。
こういった時には、hiddenメンバを利用します。 hiddenは、primaryからのデータコピーはしているものの、読み込みの対象となることはありません。 そのため、書き込みを止めてしまっても誰にも影響がなく、安心して止めることができます。 ただ、バックアップが終わった後は、書き込み処理(primaryからのデータコピー)の再開を忘れないでおく必要があります。 忘れてしまった場合、最新のデータと乖離した古いデータをバックアップ対象としてしまうことになります。
なおテスト運用を行った際、バックアップジョブのバグにより"hiddenの書き込み停止が解除されないまま"になってしまっていたことがありました。 これは、監視項目にreplication lag(primaryとの間にどの状態差分が存在するか)を追加することにより検知できるようになりました。
さいごに
駆け足となりましたが、MongoDBクラスタの構築運用についてでした。 安定稼働や状況変化への対応を考慮した設計が求められる点がバックエンド技術の大変なところであり、楽しいところでもあります。
なお、置き換えによりCosmosDB利用時に生じていた問題が解消されたため、現在は置き換えた状態で運用を行っております。 (繰り返しになりますが、この問題はあくまで"CIOSのユースケースの場合"に生じたものであることに注意してください。)
OPTiM では一緒に働く仲間を募集しています。 興味を持もたれた方はぜひお問い合わせをお願います! 佐賀本店、九工大オフィスでは研究開発アルバイトスタッフも募集中です!!