

こんにちは、プラットフォーム開発ユニットの山川です。
私のチームでは、プラットフォームエンジニアリング (以後PEと表記)の活動の一環として、社内の開発者向けのマルチテナントなEKSクラスタを構築・運用しています。 本記事ではそのプラットフォーム上でGrafana Stackによるモニタリング基盤を構築した件について紹介させていただきます。
弊社のPEの活動については以下の記事もぜひご覧ください。
tech-blog.optim.co.jp
モニタリング基盤を構築するに至った背景
前述したように、弊社ではPEの活動の一環として社内の開発者向けのマルチテナントなEKSクラスタを運用しています。EKSクラスタの利用者である社内の開発者は、割り当てられたテナントで各々が担当しているプロダクトの開発・運用を行っています。
各テナントチームはPEチームから提供されているサービス以外は自前で構築しており、例えばRDS等のプロダクト固有のリソースがそれにあたります。プロダクトのモニタリング環境についてもテナントチームが自前で構築しています。 そのためモニタリング環境を実現するためのパイプライン、バックエンド、ビジュアライズツールの構築であったり、ダッシュボード、アラートの設定などは全てテナントチームが0から行っていました。
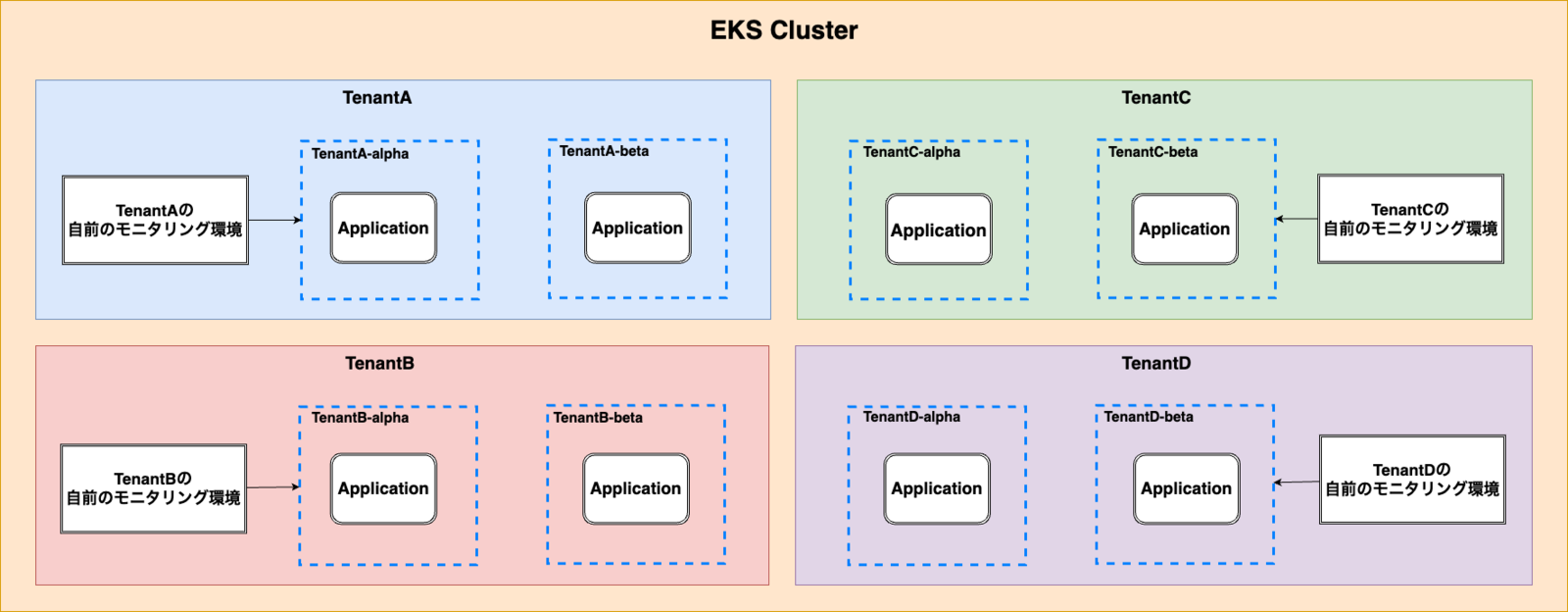
しかしモニタリング基盤の構築・運用はプロダクトの価値創出という意味で、テナントチームにとって本質的な活動であるとはいえません。PEの観点としても、そういった不要な認知負荷を下げる環境の構築を推進する必要があると言えました。
また認知負荷という観点だけではなく、以下の側面からも潜在的な課題がありました。
- コスト効率化
- モニタリング環境のチューニングが疎かになり、監視コストが増大しがち
- コードの再利用
- テナントごとに採用する監視ツールが異なると、IaCによるコードの再利用が難しくなる
- 知見の分散
- 監視に関するベストプラクティスや、メトリックやログを抽出するクエリに関する知見などが社内で分散してしまう
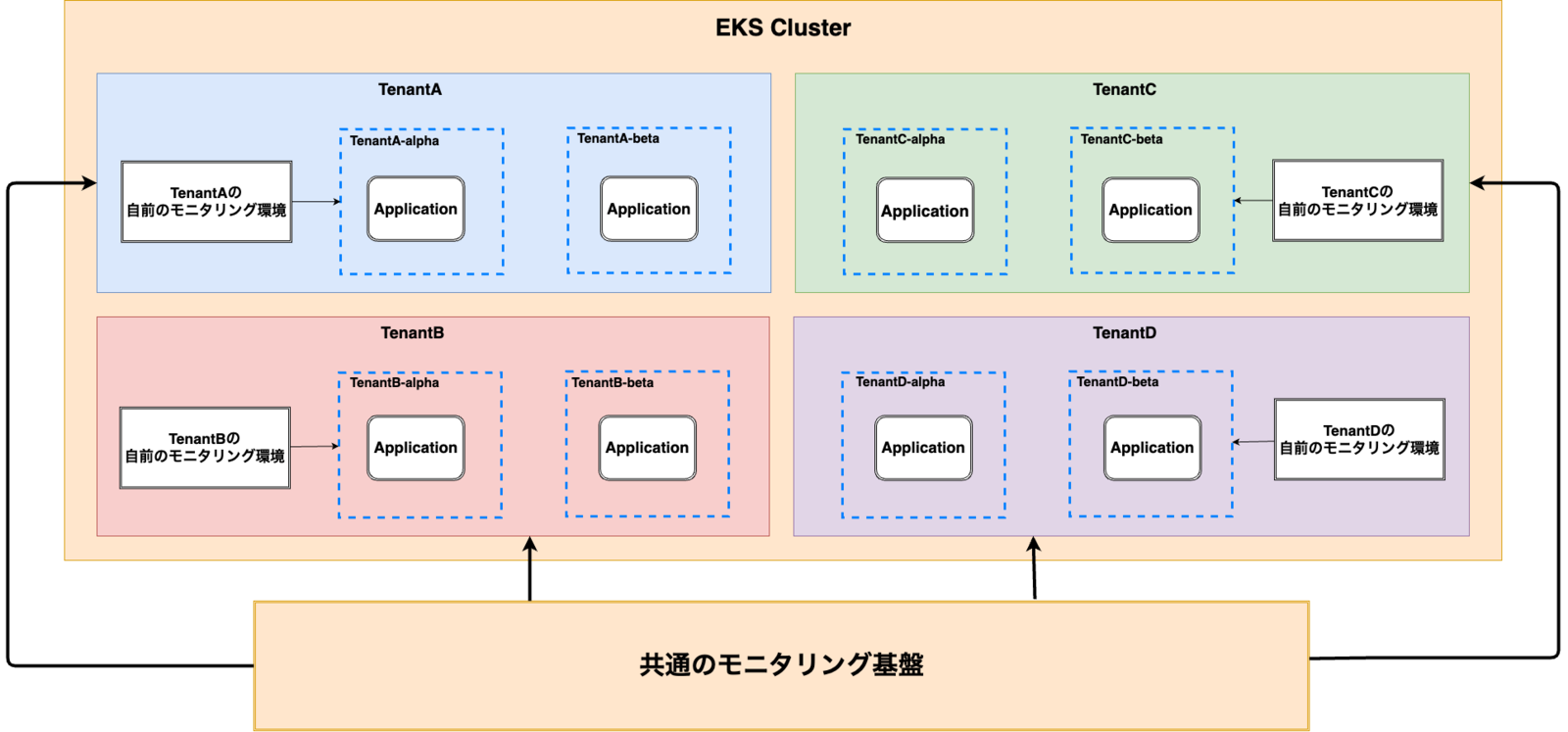
よって上記のような背景・課題を解決するために、以下の図に示すような、共通的なモニタリング基盤を構築する必要がありました。
Grafana Stackを採用した理由
本記事の主題にあるように、モニタリング基盤で利用するツールとしてGrafana Stackを採用しました。
Grafana Stackを採用した主な理由は以下です。
- コストが低い
- Grafana StackはデータのストレージにS3バケットを利用できるため、一般的なSaaSと比較してコストが低く済む
- コード化が容易
- HelmやTerraformを利用することで、リソースのデプロイから、ダッシュボード、アラートの設定までコード化が可能
- テレメトリーデータの相関が可能
- Grafana上でログ、メトリック、トレースを解析でき、それぞれの相関が可能
- マルチテナントに対応
- バックエンドがマルチテナントに対応しているため、リソースの効率化、テナント間のアクセス制御などが可能
- デファクトスタンダードであるPrometheusの仕様をベースにしている
- モニタリングに関する社内の知見を深めていく上で、Prometheusの仕様をベースとしていて、尚且つ、今後の成長性も見込めるGrafana Stackを採用する価値が高い
モニタリング基盤のアーキテクチャ
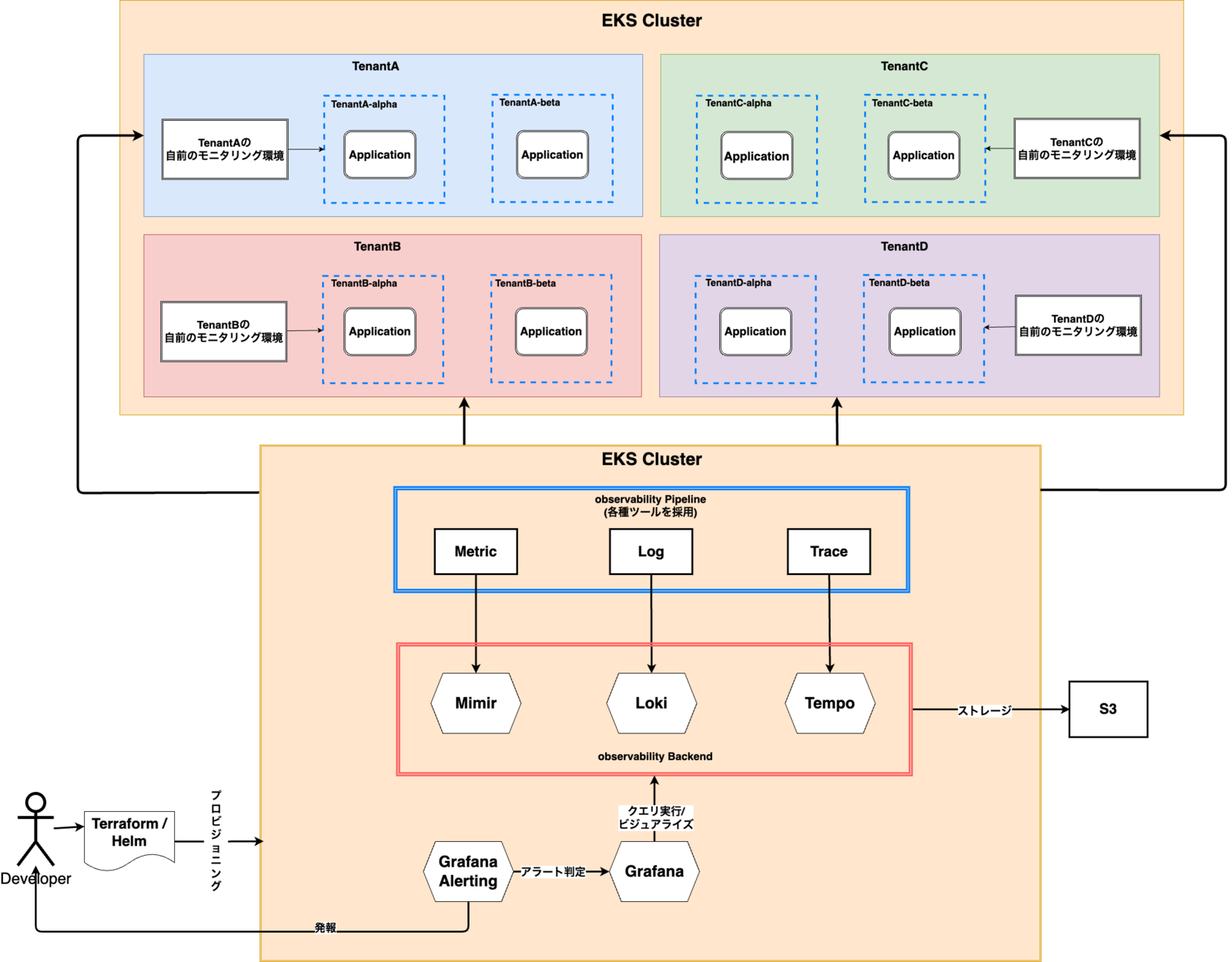
Grafana Stackを利用したモニタリング基盤は以下のようなアーキテクチャをとっています。
メトリックの保管にはMimir、ログの保管にはLoki、トレースの保管にはTempoを利用します。それぞれのストレージにはS3バケットを採用しています。データの参照にはGrafanaを利用し、Mimir、Loki、Tempoをデータソースとして設定した上で、クエリをリクエストし、その結果をビジュアライズします。
アラートについてはGrafana Alertingを利用しており、メトリック、ログを介してのアラートの実装を可能としています。 また、それらのリソース群のデプロイと、Grafana上のダッシュボード、アラートの設定はTerraform、Helmによってプロビジョニングしています。
マルチテナントの実現
前述したようにGrafana Stackのマルチテナント機能を活用しています。
マルチテナントを有効化する際、データの分離やアクセス制御で工夫した点について以下で説明します。
Grafana Stackのマルチテナントの仕様
前提として、Mimir、Loki、Tempoではデータの保管リクエストのHTTPヘッダに「X-Scope-OrgID: テナント識別子」を付与することで、データをテナントごとに論理的に分離させた状態で保管することができます。特定のテナントのデータを参照する場合は、参照リクエストに「X-Scope-OrgID: テナント識別子」を付与することで特定のテナントのデータを対象とした抽出処理が可能となります。
X-Scope-OrgIDを動的に付与する
テレメトリデータをGrafana Stackのバックエンドへ保管する際、データの出力元のテナントを動的に判定した上で、対応するテナント識別子をX-Scope-OrgIDに付与する必要があります。この仕組みについてはnamespaceのLabelと、パイプラインのデータ変換処理で実現しています。
下の図に示すようにnamespaceのtenant/idラベルにテナント識別子を紐づけておきます。パイプラインがテナントのサービスからテレメトリデータを受け取った際、そのデータの送信元の情報からnamespaceの情報を取得し、それに紐づけてtenant/idラベルの値も取得します。ラベルの値(テナントの識別子)をX-Scope-OrgIDヘッダに設定した上でパイプラインからバックエンドに保管リクエストを送ることで動的なX-Scope-OrgIDの付与を実現しています。
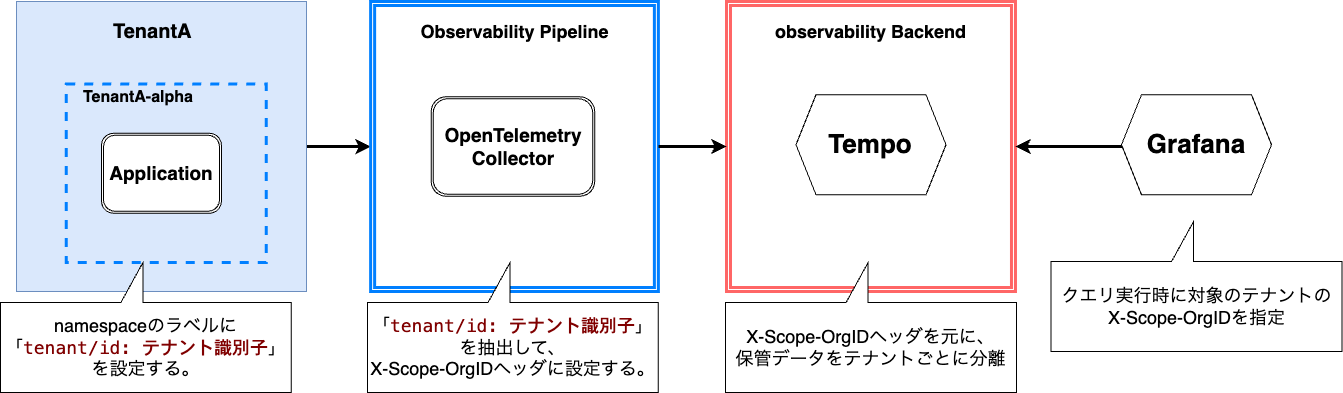
GrafanaのOrganizationによる権限の分離
Grafana上ではテナントごとにOrganizationを分離しており、Datasourceの設定で指定できるX-Scope-OrgIDを制御しています。Datasouceの設定はテナント側では変更できないように設定されているため、テナント間でのデータの参照はできないようになっています。またOrganizationに対するアクセス制御は社内ID基盤を利用しており、社内ID基盤の認証グループとOrganizationを紐づけることで、テナントのユーザがアクセスできるOrganizationを制御しています。
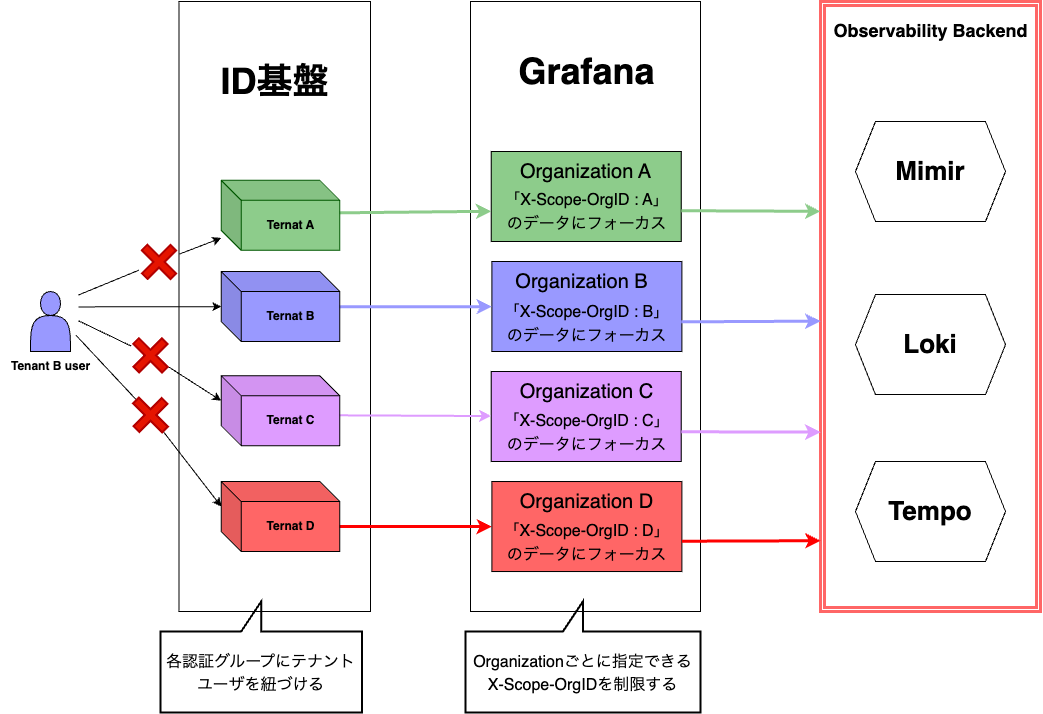
以上の仕組みによってGrafana Stackのマルチテナント機能を活用しています。これによってテナント単位で独立したシングルテナントのGrafanaの管理を避け、またテナント間でのデータのアクセス制御を実現できました。
テナントチームの認知負荷の低減の効果
モニタリング基盤はPEチームが管理しているため、テナントチームはパイプラインやバックエンドの存在を意識せずに透過的にモニタリングを行うことができます。メトリック、ログは基本的に自動的に収集されるように設定されており、トレースに関してもあらかじめ用意されているパイプラインのエンドポイントに送信するように設定するだけで済みます。
データを参照する際は前述したように社内ID基盤経由でGrafanaへとアクセスし、ダッシュボード、Explore等を利用してクエリを実行することになります。ダッシュボードについてはPodのリソースのutilizationなどの共通的なパネルはデフォルトで構築されており、テナントチームはそのデフォルトのダッシュボード以外で必要なものがあればカスタムして追加することが可能です。これはアラートについても同様で、テナントチームはPEチームを介さずにダッシュボード、アラートをカスタムできます。
よって、テナントチームは自前で運用していた時と比較して、認知負荷を大きく低減した状態でモニタリングを行うことが可能となっています。
まとめ
Grafana Stackによるモニタリング基盤の構築により、テナントチームのモニタリングに関する認知負荷を下げるための環境を提供できるようになりました。
しかし、この取り組みは発展途上の段階にあり、テナントごとのデータの保持期間の制御や、ログ・メトリック・トレースの相関の網羅性向上、クエリの最適化など、機能拡充やパフォーマンスに関する課題がまだまだ残っているため、継続的にブラッシュアップを続けていく予定です。
OPTiMでは、本稿で紹介したPEの活動や、そのプラットフォーム上で運用されている弊社のプロダクトの開発に協力いただけるメンバを募集しています。