

R&D チームの徳田(@dakuton)です。 最近、spaCyの日本語版モデルが正式サポートされたのでいろいろ触ってみたところ、解析結果ビジュアライズを全部まとめるStreamlitアプリも同じ月に提供されていることがわかったので、今回はそちらを紹介します。 なお、ビジュアライズ機能の一部(係り受け解析)は1年前の記事「その他」で紹介しています。
実行手順
spaCyのUniverseプロジェクトであるspacy-streamlitをインストールします。
pip install spacy-streamlit
起動用スクリプト(streamlit_app.py)
import os import pkg_resources, imp import spacy_streamlit models = ["ja_core_news_lg", "ja_core_news_md", "ja_core_news_sm"] # 未ダウンロードのモデルファイルがある場合はダウンロード for model in models: try: imp.find_module(model) except ImportError: os.system("python -m spacy download {}".format(model)) imp.reload(pkg_resources) spacy_streamlit.visualize(models, "")
実行(pythonではなくstreamlitコマンドで起動)
streamlit run streamlit_app.py
実行サンプル
インターン募集ページのエントリー(R&D)にある要項を解析してみました。
【サマーインターン’20】R&D(研究開発)コース -「ネットを空気に変える」をAI×IoT×Robotで実現しよう AI×IoT×Robotを組み合わせた高度な技術を、誰でも使えるサービスにしているオプティムでインターンシップをしませんか? 農業・医療・建設など、日本や世界にはまだまだITサービスを活用しきれていない業界が数多くあります。 オプティムのインターンシップでは、そういった現場で使えるサービスのコアとなる技術開発を体験することができます。 オプティムでは、これまで積み上げてきた技術スキル・知見を一度リセットすることを恐れず、 ゼロから勝負する文化が根付いています。業務未経験でも新たな分野にチャレンジしたい方はぜひ応募ください。 ●定員:最大30名 ●概要 R&D(研究開発)コースでは、AIの研究開発に携わっていただきます 主にGPU環境で機械学習を使った画像解析系AIの開発をしていただきます ▽過去テーマ ・深層学習を使った商品ランク分類 ・医療画像解析(眼底など)の精度改善 ・人以外に対する行動認識の適用調査 ・エッジデバイスを用いた推論有効性の調査
係り受け解析(Dependency Parsing)
1文ずつ表示してくれます。
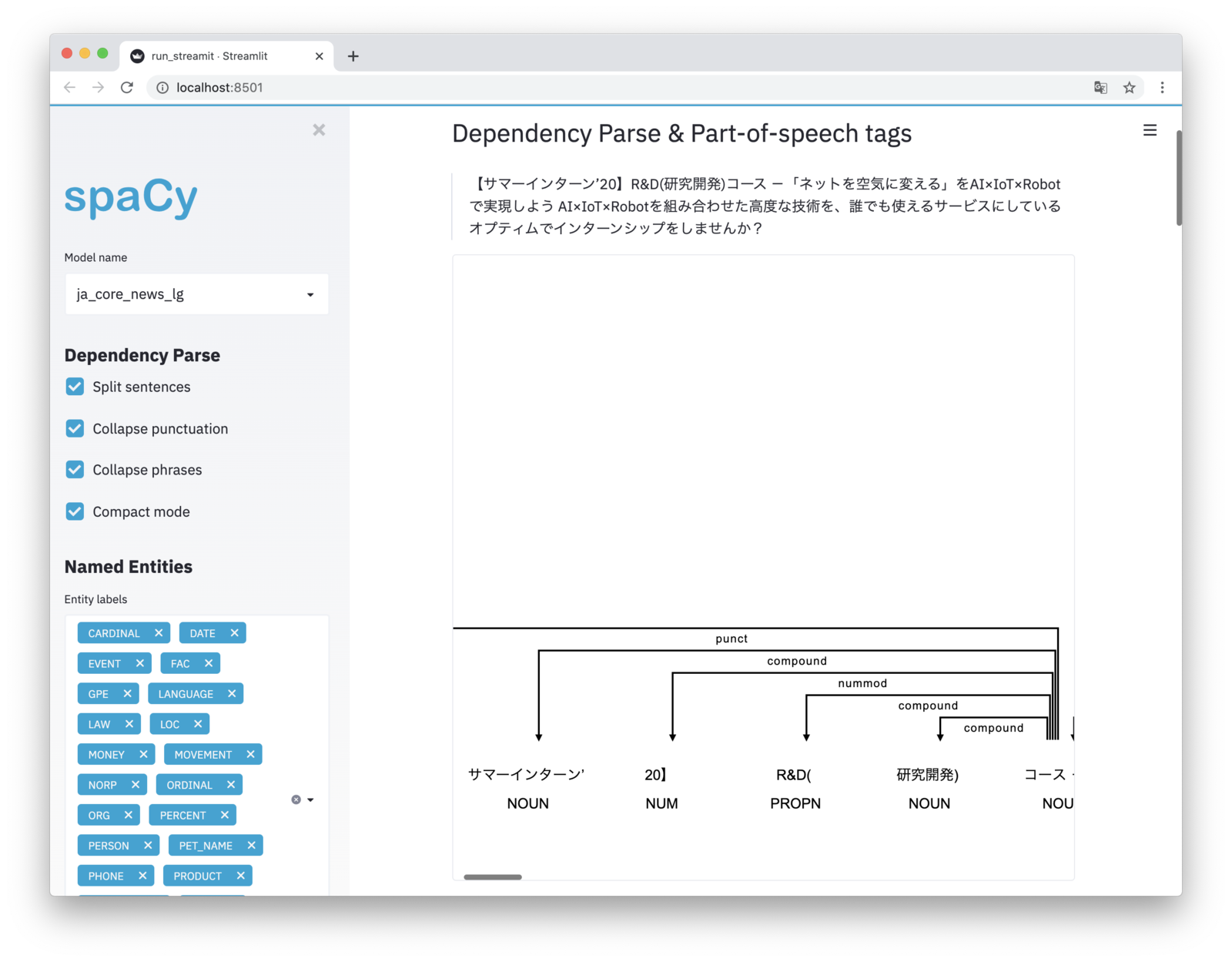
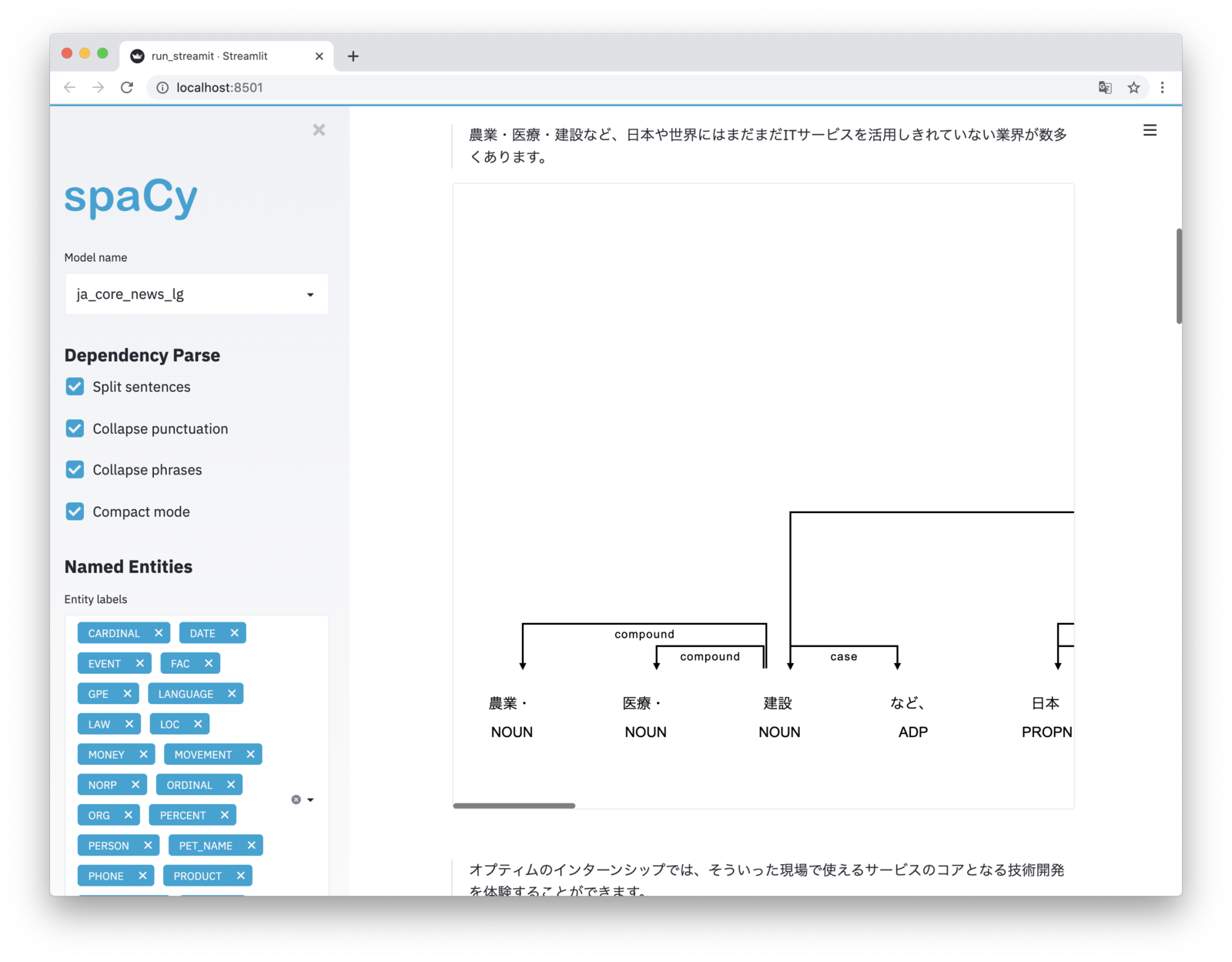
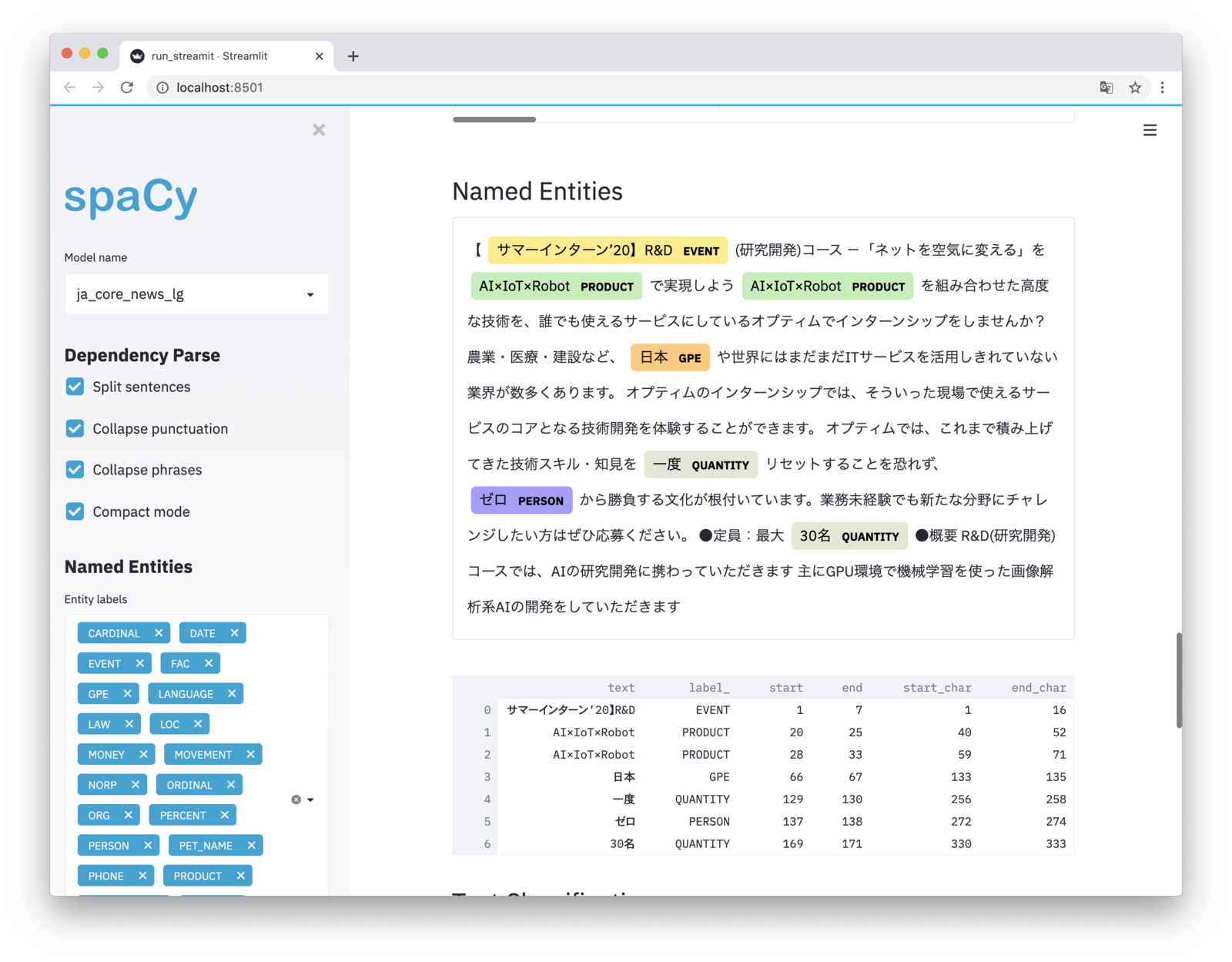
固有表現抽出(Named Entity Recognition)
固有表現抽出(文の中から人名、組織名、地名などを取得する手法)によるハイライト表示はこちら。
日本語モデルだと精度(NER accuracy)は70%前後ではありますが、国名、地名や数量表現は問題なく取得できるようです。
ただしカタカナが人名として検出されたり、組織名(企業名)が取得できないケースはあります。複合名詞(名詞が単語として連接する場合)としてまとまった状態にはなっているため、この結果を手がかりにmecab-ipadic-NEologdなど他の辞書で結果補正をかけるとよいでしょう。
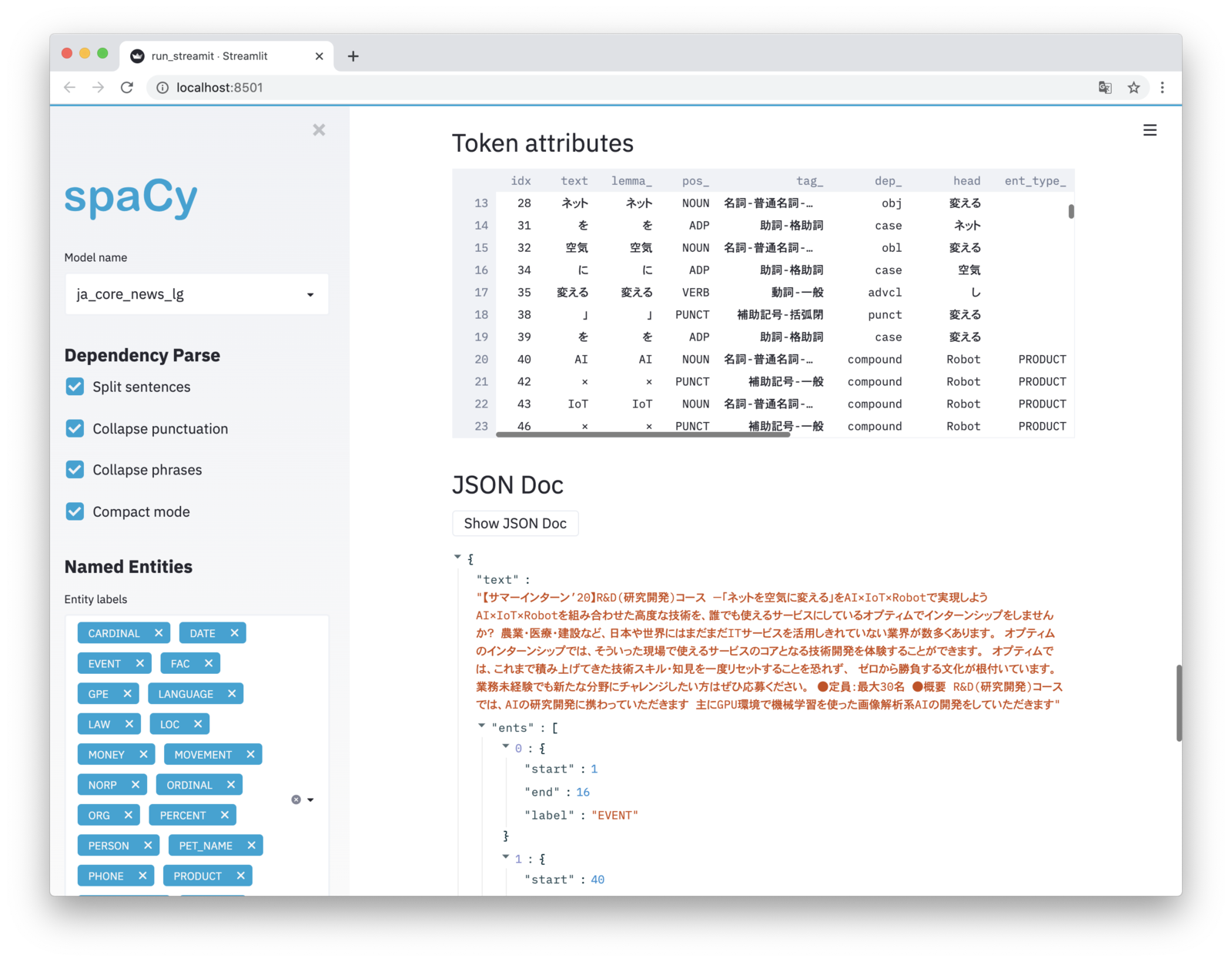
形態素解析(Morphological Analysis)+JSON
形態素解析(品詞情報をもとに単語を最小単位へトークン分解し、品詞を付与)やJSON結果もあわせて表示されます。
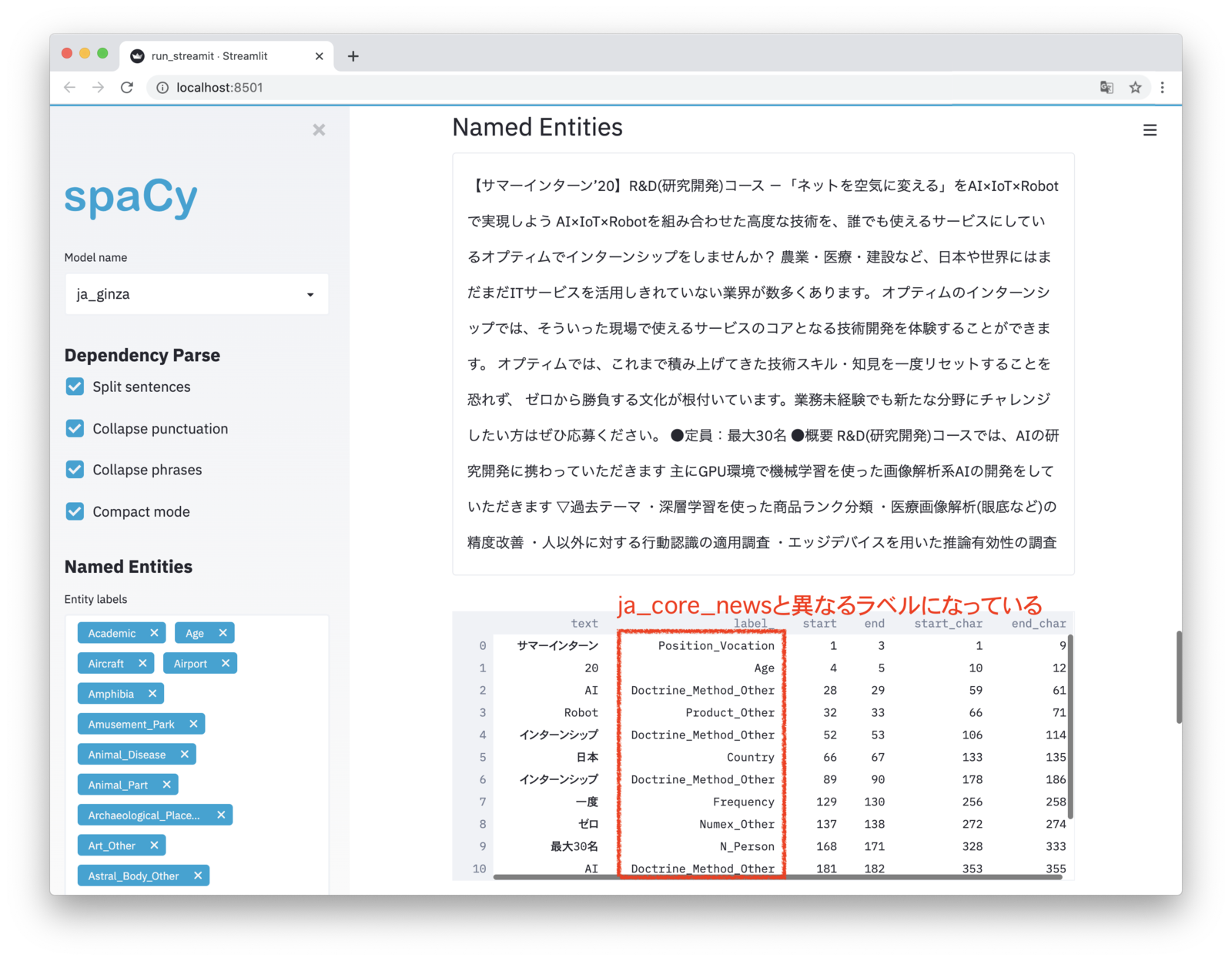
GiNZAとの結果比較
spaCy互換日本語モデルであるGiNZA(pip install ginza)でも試してみました。
固有表現抽出は固有表現ラベルのマッピングがとれておらずハイライトされなかったのですが、係り受け解析は問題なく使えました。
おわりに
StreamlitはWebオンタイムでパラメータ調整可能なYOLOv3物体検出デモができるなど、Python可視化ライブラリのなかでも最近勢いを感じていたので、自然言語処理でもspaCyがもともと持っている可視化部分をさっと取り込めるのは非常に便利だと思いました。
あらためて、今回用いたデータはこちらです。(2020年度の募集は締め切りました。多数応募いただきありがとうございます。) www.optim.co.jp
それ以外の採用ページはこちらです。 www.optim.co.jp