お久しぶりです、R&Dの加藤です。最近は「A列車で行こう~はじまる観光計画~」をコツコツ進めていますが楽しいですね。Steamでも公開されるそうなのでNintendo Switchを持っていなくてもプレイできますよ。
さて、今回はDeep Learningによる異常検知デモを作成したので説明します。
デモ動画
まずはデモ動画を観てください。
回転レーン上のブロックを撮影し、ブロックの位置(Infer image[2])とゲート跡(Infer image[1])を検出する様子です。
解説
動画の各部位の説明をします。

[1] 撮影動画
[2] 前処理済み入力画像1: Input image [1]
[3] 前処理済み入力画像2: Input image [2]
[4] 入力画像1に対する推論結果: Infer image [1]
[5] 入力画像2に対する推論結果: Infer image [2]
[A] すべての推論にかかった時間
[B] 入力画像の作成用に切出した領域
流れとしては、撮影動画 [1] から [B] の領域部分を切り抜き、モノクロ画像処理などの前処理を加えたものが [2]、[3]です。 [2]、[3]をそれぞれ別のDeep Learningモデルで推論した結果が [4]、[5]でそれにかかった時間が [A]になります。
Deep Learningモデルについて話すと長くなってしまうので詳細は省略しますが、ブロックの位置を検出するモデルとゲート跡を検出するモデルを用意しました。ちなみにゲート跡というのはプラスチック成型時にできる凹凸の事です。
Infer imageの赤色部分が、実際にDeep Learningで推論された結果で、緑色部分が推論結果から後処理を加えて可視化したものです。わかりやすく、推論だけをInfer image [1]に、推論と後処理の組み合わせたものをInfer image [2]に配置した動画がこちらです。
※ Input image [1]と[2]は同じ画像
※ Infer image [1]、[2]で使用しているモデルは同じ
※ Infer image [1]と[2]の違いは後処理の有無のみ
後処理の例として今回は下記画像にあるように、ブロックの位置(Infer image [2])とゲート跡(Infer image [1])の検出をさせています。

ブロック位置は、推論結果を16x16の画像にリサイズして再度リサイズして元のサイズに戻しています。この手順を利用することでワークの情報を残しつつノイズを除去できます。最後にワーク数をOpenCVの領域検出を利用して計算しています。ゲート跡の位置も同様に領域抽出して計算しています(こちらは中心座標を描画しています)。

上記のデモはU-Net(セグメンテーション)系モデルを使って400枚程度の画像で訓練させました。
Deep Learningというと、数千枚、場合によっては数万枚の画像を用意する必要がありますがある程度撮影環境と検出対象を限定することで少ない枚数でも十分実現できます。
撮影環境とアノテーション
補足ですが、こんな感じで撮影しています。

カメラの反対側に設置してあるのはRGBライトです。ゲート跡を浮かび上がらせるために使用しています。
アノテーションはこんな感じでやりました。
アノテーションツールはOpenCVを使って自作しています。ブロックのアノテーション後にゲート跡のアノテーションを実施していますが、ブロックのアノテーションは縁取りが難しいのでAIを使って補正しています。動画は2倍速です。
アノテーションしたものをデータセットとこの記事では呼びます。今回はこのデータセットを分離してブロック検出とゲート跡検出の正解画像を作成します。

Deep Learningによる異常検知の速度と精度の話
セグメンテーション系のタスクはほとんどの場合U-Net系がシンプルかつ高精度な結果を出してくれます。 U-Netに限らず、Deep Learningは小さい物体(≒情報量の少ない対象)が苦手という特徴もありますが、それを解決するためにスキップ機構などの工夫が入っているモデルも存在します(図中の青矢印や緑矢印のこと)。
下図の白い箱がDeep Learningモデルの階層を表現しています。処理が進むにつれてこの白い箱の縦横サイズが小さくチャンネルは大きくなり、ずんぐりむっくりして、元に戻っていき推論結果が出力されていくイメージです。この形状がU字に見えることからU-Netと呼ばれています。
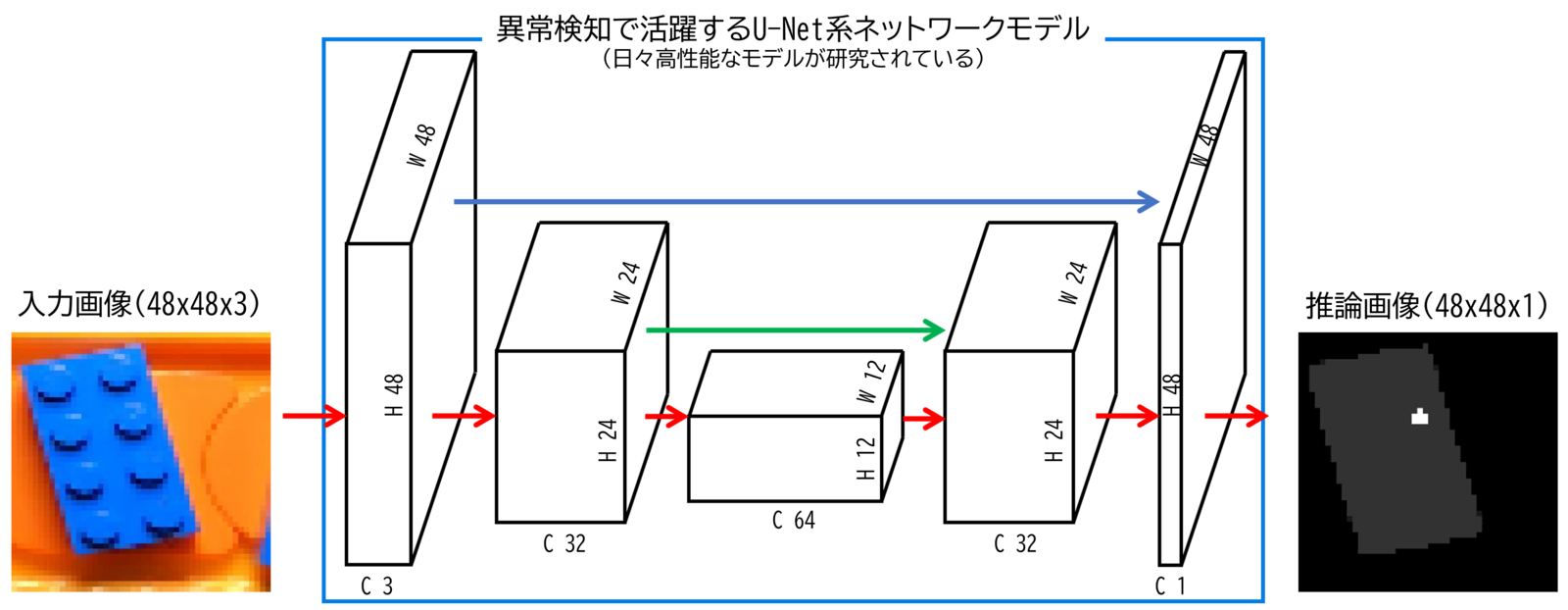
U-Net系でおススメはU-2-NetやAttention U-Netですね。
速度改善する方法
小さい物体の検出精度を上げる簡単な方法は画像サイズを大きくすることですが、画像サイズを大きくすると推論に時間がかかってしまいます。
異常検知はリアルタイム性が求められることが多いので、画像サイズはなるべく小さくしてギリギリを狙っていきたいですね。
以下は冒頭の動画のブロックの位置(Work)とゲート跡(Point)の推論速度の計測結果になります。

画像サイズはPointが768x768でWorkは96x96です。Workの方がタスクとしては簡単なので、画像サイズを小さくしています。推論(Infer)は初回だけ時間がかかっていますが2回目以降は70ms弱(≒15FPS)の速度が出ています。
Otherは動画からの画像読込みや後処理にかかる時間です。
15FPSあれば多くの場面でリアルタイム性を担保できると思います。
推論環境は、Deep LearningモデルをONNX化して、onnxruntime-gpuで推論しています。 GPUはGeForce GTX 1080 Tiで、CPUはIntel Xeon CPU E5-2660 v3 @ 2.60GHzです。
ONNX化については公式のチュートリアルが参考になります。
次の動画は画像サイズを変えた場合の検知精度を比較したものになります。 画像サイズを48x48まで小さくしたのがInput image[1]で、768x768がInput image[2]になります。 48x48まで小さくすると誤検知が増えているのが良くわかると思います。
※ Input image [1]と[2]は画像サイズが異なる
※ Infer image [1]と[2]で使用しているモデルは別
入力画像を拡大してみると、(当然ですが)ゲート跡が小さくなっていますね。

196x196くらいまではゲート跡が数ピクセルで目視できますが、48x48では1ピクセルしかなく、目視での判断が困難です。 目視で判断できるかどうかは、Deep Learningが活用できるかどうかのひとつの指標になります。
参考に、768x768から196x196まで画像を小さく(≒1/4)すると推論速度は2倍程度高速化されます。これで30FPSですね。

処理速度を上げるためには、画像サイズもそうですが画像のモノクロ化も有効です。カラー画像をモノクロ画像にするだけでチャンネル数を1/3にできるので高速化にかなり貢献できます。
ちなみに、ブロック検出とゲート跡検出はどちらもモノクロ画像化しているのですが、ゲート跡検出は一般的なグレースケール化をしていますが、ブロック検出はデータセットから青色成分を抽出してモノクロ画像にしています(青色ブロックに特化しているため)。

このように、選択するチャンネルを変えるだけで画像の印象が大きく変わってきます。
Deep Learningとチャンネル
小さい物体がなぜ苦手なのか?そのヒントはチャンネルの理解が重要です。
ここからはそのチャンネルについて初学者向けに解説します。
モノクロ画像とカラー画像
モノクロは一色で構成されています。カラーはRed(R)、Green(G)、Blue(B)の三色の構成で様々な色味を表現します。 0-255の8bitの三色で24bitカラーを使用しています。これは1677万色再現でき、フルカラーやトゥルーカラーとも呼ばれます。

RGBの事をカラーチャンネルと呼び、表記はchとかCとか色々あります。カラー画像は3ch、モノクロ画像は1chですね。
カラー画像(3ch)を超えた、4chの画像も存在する
ちなみに、世の中には4チャンネル目が存在する場合があります。下図のようなアルファチャンネルとDepthチャンネルがいい例ですね。

アルファチャンネルはPNGデータ等でもおなじみかもしれません。画像の透過部分を表現したチャンネルです。画像を重ね合わせる時にキレイに重ねられます。 Depthチャンネルはあまりなじみがないかもしれませんが、カメラからの距離を表現しています。上の図では、近いほど青く、遠いほど赤くなります(距離が計算できない部分は濃い青です)。
Depthは流行りのLiDAR等でも取得できますが、個人的にはOAK-Dのステレオ視が好きですね。コンパクトなLiteもあります。
コロナ禍で顔を近づけると温度を測ってくれる端末をよく見かけるようになりましたね。熱を感知するサーモグラフィとRGB画像を重ね合わせれば、それも4ch画像といえます。
Deep Learningにおける畳込みとチャンネル
チャンネルについて簡単に説明しました。ここからはもう少しDeep Learning寄りの話になります。
Deep Learningの肝はDeep Learningモデルの無数のパラメータです。この無数のパラメータを大量の学習によって決定することを学習と呼びます。 この無数にあるパラメータを人間がひとつずつ確認する事は不可能であり、これが「Deep Learningはブラックボックスだ」と言われてしまう一因です。 この、無数のパラメータの大部分は(少々乱暴ですが)畳込みと呼ばれる処理によって構成されています。
畳込みを超ざっくり説明すると、
- 画像サイズ(HxW)を小さく、チャンネル(C)を増やす
- 画像サイズ(HxW)を大きく、チャンネル(C)を減らす
という処理を実施しています。下図の白い箱がDeep Learningモデルの階層を表現しています。

※ 画像サイズを大きくしていく畳込みは一般的に逆畳込み(もしくはアップサンプリング)と呼ばれています
※ 画像サイズを変更しているのは厳密にはプーリングですが、ネットワークモデル内部を触るエンジニアでもなければあまり重要ではないです
今まで多くてもせいぜい4チャンネルでしたが、Deep Learningになると64チャンネルも出てきました。当然ですが実際のDeep Learningモデルはもっと数が多くなりますが、チャンネル数が増えると処理も増えることに注意しましょう。
最後に
今回は異常検知デモ①とチャンネルについての解説でした。推論速度を改善するには画像サイズとチャンネル数を減らすのが一番という事が伝わっていれば嬉しいです。異常検知をやるにあたっては、「目視で異常がわかるか?」というのも重要になります。評判が良ければ(+良さそうなネタが見つかれば)②、③とシリーズ化していきますので、ブクマとTwitter拡散よろしくお願いします。
ついでですがDeep Learningしたい方、もしくはそれに関わる方々におススメなのでついでに紹介します。実際に業務で機械学習を進める上での注意点やハマりポイントを紹介しています。斜め読みなら数時間で読めますよ。少しでも悲しいPoCを世に生み出さないために、(特に)機械学習エンジニアをとりまく老若男女に広く読んで欲しい一冊です。第2版になってパワーアップしています。
OPTiMでは画像、時系列問わず異常検知やりたいエンジニアを募集しています。