こんにちは、R&D チームの宮城です。画像分類モデルの開発や精度改善などの業務を担当しています。
最近は将棋観戦にはまっており、藤井聡太先生の対局を見まくっていますが一向に将棋が強くなる気配はありません。
今回の記事ではディープラーニングモデル圧縮手法の一つ、Pruning を PyTorch で簡単に試してみました。
Pruningとは
Pruningについては下記の記事が大変参考になりました。内容をかいつまんで説明します。
Compress & Optimize Your Deep Neural Network With Pruning
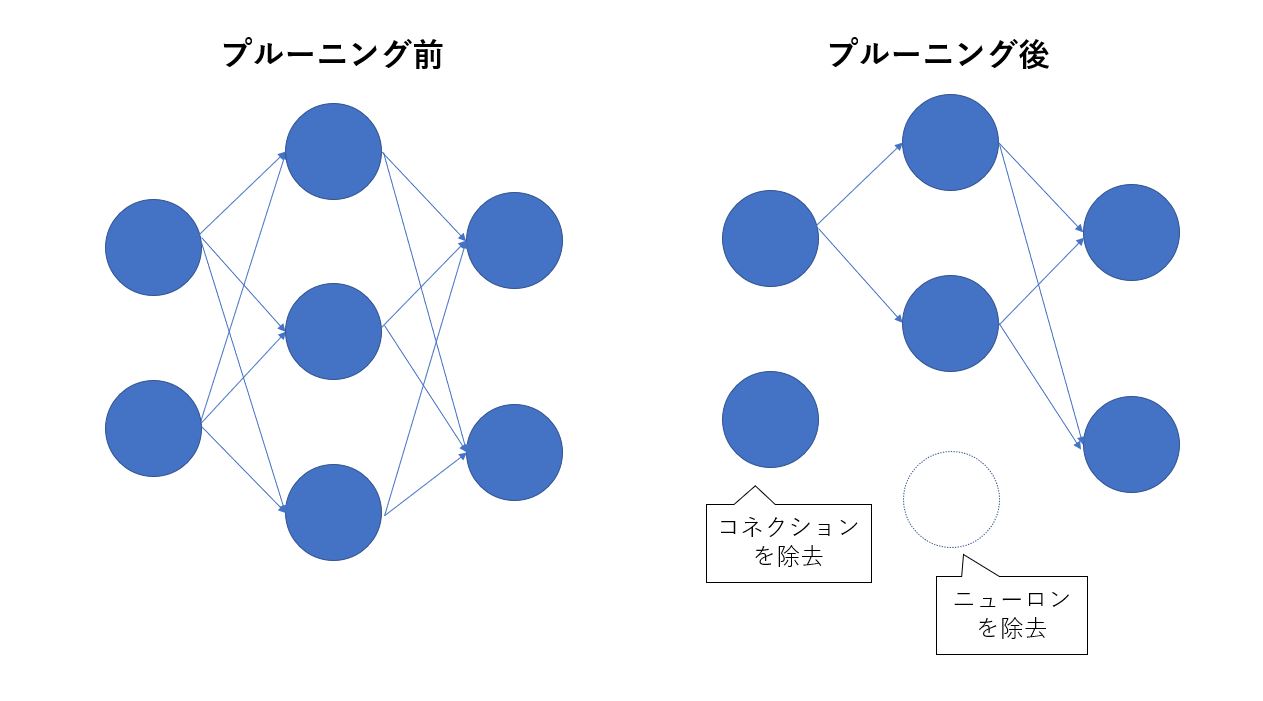
上図のように、Pruningとはニューロン間のコネクション(繋がり)やニューロンそのものを除去することでモデルを圧縮する手法で、大きく以下の2種類に分けられます。
UnStructured Pruning(非構造的Pruning) → ニューロン間のコネクションを除去する。ネットワークの構造は変化しない
Structured Pruning(構造的Pruning) → ニューロンそのものを除去する。ネットワークの構造が変化する
この記事で試してみるのは 1. UnStructured Pruning(非構造的Pruning) です。
PyTorch で Pruning お試し
のコードを参考にモデルを訓練後にPruningを実施し、精度変化などを確認してみます。
以下、Google Colab (PyTorch 1.9.0) で動作確認しました。
データセットを用意
まずは必要なライブラリをimportし、
今回使用する10クラスの画像分類データセット CIFAR10 をダウンロードします
import torch from torch import nn import torch.nn.functional as F
import torchvision from torchvision import datasets, transforms transform = transforms.Compose( [transforms.ToTensor(), transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))]) trainset = torchvision.datasets.CIFAR10(root='./data', train=True, download=True, transform=transform) trainloader = torch.utils.data.DataLoader(trainset, batch_size=4, shuffle=True, num_workers=2) testset = torchvision.datasets.CIFAR10(root='./data', train=False, download=True, transform=transform) testloader = torch.utils.data.DataLoader(testset, batch_size=1, shuffle=False, num_workers=2) classes = ('plane', 'car', 'bird', 'cat', 'deer', 'dog', 'frog', 'horse', 'ship', 'truck')
CIFAR10の画像サンプルを確認してみます。
import matplotlib.pyplot as plt import numpy as np def imshow(img): img = img / 2 + 0.5 npimg = img.numpy() plt.imshow(np.transpose(npimg, (1, 2, 0))) plt.show() # 訓練データをランダムに取得 dataiter = iter(trainloader) images, labels = dataiter.next() # 画像を表示 imshow(torchvision.utils.make_grid(images)) # クラスラベルを表示 print(' '.join('%5s' % classes[labels[j]] for j in range(4)))

CIFAR10 の画像はサイズ32x32と小さく、クラスを分類するのがなかなか難しそうです。
モデル作成
次にモデルを作成します。 Pruningチュートリアルでは畳み込み層2つ、全結合層3つの小さめのモデルを使用していますが、ここではもう少し層が深いモデル VGG16 を使ってPruningの効果を確認してみます。
from torchvision import models model = models.vgg16(pretrained=False, num_classes=10) criterion = torch.nn.CrossEntropyLoss() optimizer = torch.optim.SGD(model.parameters(), lr=0.001, momentum=0.9) device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu") model.to(device)
VGG16 のレイヤー名等、モデル構成は以下の通りです。
VGG(
(features): Sequential(
(0): Conv2d(3, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): ReLU(inplace=True)
(2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(3): ReLU(inplace=True)
(4): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(5): Conv2d(64, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(6): ReLU(inplace=True)
(7): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(8): ReLU(inplace=True)
(9): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(10): Conv2d(128, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(11): ReLU(inplace=True)
(12): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(13): ReLU(inplace=True)
(14): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(15): ReLU(inplace=True)
(16): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(17): Conv2d(256, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(18): ReLU(inplace=True)
(19): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(20): ReLU(inplace=True)
(21): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(22): ReLU(inplace=True)
(23): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(24): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(25): ReLU(inplace=True)
(26): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(27): ReLU(inplace=True)
(28): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(29): ReLU(inplace=True)
(30): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
)
(avgpool): AdaptiveAvgPool2d(output_size=(7, 7))
(classifier): Sequential(
(0): Linear(in_features=25088, out_features=4096, bias=True)
(1): ReLU(inplace=True)
(2): Dropout(p=0.5, inplace=False)
(3): Linear(in_features=4096, out_features=4096, bias=True)
(4): ReLU(inplace=True)
(5): Dropout(p=0.5, inplace=False)
(6): Linear(in_features=4096, out_features=10, bias=True)
)
)
ベースとなるモデルを訓練
for epoch in range(2): running_loss = 0.0 for i, data in enumerate(trainloader, 0): inputs, labels = data[0].to(device), data[1].to(device) optimizer.zero_grad() outputs = model(inputs) loss = criterion(outputs, labels) loss.backward() optimizer.step() train_loss = loss.item() running_loss += loss.item() if i % 2000 == 1999: print('[%d, %5d] loss: %.3f' % (epoch + 1, i + 1, running_loss / 2000)) running_loss = 0.0 print('Finished Training') torch.save(model.state_dict(), "cifar10_vgg16.pth.tar")
モデルをPruning
いよいよ訓練済みのモデルをPruningしていきます。
ここではモデル全体に対して一定の割合で重みを Pruning する Global Pruning を使用します。
下の例でのPruning対象はモデルの畳み込み層、全結合層の weight で、Pruningの割合は30%です。
import torch.nn.utils.prune as prune # prune_amount amount = 0.3 pruned_model = models.vgg16(pretrained=False, num_classes=10).to(device) pruned_model.load_state_dict(torch.load('cifar10_vgg16.pth.tar')) parameters_to_prune = ( (pruned_model.features[0], 'weight'), (pruned_model.features[2], 'weight'), (pruned_model.features[5], 'weight'), (pruned_model.features[7], 'weight'), (pruned_model.features[10], 'weight'), (pruned_model.features[12], 'weight'), (pruned_model.features[14], 'weight'), (pruned_model.features[17], 'weight'), (pruned_model.features[19], 'weight'), (pruned_model.features[21], 'weight'), (pruned_model.features[24], 'weight'), (pruned_model.features[26], 'weight'), (pruned_model.features[28], 'weight'), (pruned_model.classifier[0], 'weight'), (pruned_model.classifier[3], 'weight'), (pruned_model.classifier[6], 'weight') ) prune.global_unstructured( parameters_to_prune, pruning_method=prune.L1Unstructured, amount=amount, ) prune.remove(pruned_model.features[0], 'weight') prune.remove(pruned_model.features[2], 'weight') prune.remove(pruned_model.features[5], 'weight') prune.remove(pruned_model.features[7], 'weight') prune.remove(pruned_model.features[10], 'weight') prune.remove(pruned_model.features[12], 'weight') prune.remove(pruned_model.features[14], 'weight') prune.remove(pruned_model.features[17], 'weight') prune.remove(pruned_model.features[19], 'weight') prune.remove(pruned_model.features[21], 'weight') prune.remove(pruned_model.features[24], 'weight') prune.remove(pruned_model.features[26], 'weight') prune.remove(pruned_model.features[28], 'weight') prune.remove(pruned_model.classifier[0], 'weight') prune.remove(pruned_model.classifier[3], 'weight') prune.remove(pruned_model.classifier[6], 'weight')
精度評価
CIFAR10データセットのテストデータ10,000件に対する Pruning前、Pruning後のVGG16モデル精度を確認してみます。
correct = 0 total = 0 with torch.no_grad(): for data in testloader: images, labels = data[0].to(device), data[1].to(device) outputs = model(images) _, predicted = torch.max(outputs.data, 1) total += labels.size(0) correct += (predicted == labels).sum().item() accuracy = 100 * correct / total print(f'Accuracy of the the Original Model on the 10000 test images: {accuracy:.1f} %') correct = 0 total = 0 with torch.no_grad(): for data in testloader: images, labels = data[0].to(device), data[1].to(device) outputs = pruned_model(images) _, predicted = torch.max(outputs.data, 1) total += labels.size(0) correct += (predicted == labels).sum().item() accuracy = 100 * correct / total print(f'Accuracy of the the Pruned Model on the 10000 test images: {accuracy:.1f} %')
出力結果
Accuracy of the the Original Model on the 10000 test images: 61.0 % Accuracy of the the Pruned Model on the 10000 test images: 60.6 %
Pruning前とPruning後でCIFAR10データセットのテストデータに対する正解率(Accuracy) が0.4%低下しています。
Pruning後の有効パラメータ数確認
total_params_count = sum(param.numel() for param in model.parameters() if param.requires_grad) pruned_model_params_count = sum(torch.nonzero(param).size(0) for param in pruned_model.parameters() if param.requires_grad) print(f'Original Model parameter count: {total_params_count:,}') print(f'Pruned Model parameter count: {pruned_model_params_count:,}') print(f'Compressed Percentage: {(100 - (pruned_model_params_count / total_params_count) * 100):.2f}%')
出力結果
Original Model parameter count: 134,301,514 Pruned Model parameter count: 94,014,788 Compressed Percentage: 30.00%
パラメータの30%がPruningされた(重みのパラメータが0になった)ことが確認できます。
Pruning後のモデルサイズ確認
Pruning前、Pruning後のモデルをZip圧縮し、ファイルサイズを確認してみます。
import os import zipfile with zipfile.ZipFile('cifar10_vgg16.pth.tar.zip', 'w', zipfile.ZIP_DEFLATED) as zf: zf.write( 'cifar10_vgg16.pth.tar') original_model_size = os.path.getsize('cifar10_vgg16.pth.tar.zip') torch.save(pruned_model.state_dict(), "pruned_cifar10_vgg16.pth.tar") with zipfile.ZipFile('pruned_cifar10_vgg16.pth.tar.zip', 'w', zipfile.ZIP_DEFLATED) as zf: zf.write( 'pruned_cifar10_vgg16.pth.tar') pruned_model_size = os.path.getsize('pruned_cifar10_vgg16.pth.tar.zip') print(f'Size of the the Original Model: {original_model_size:,} bytes') print(f'Size of the the Pruned Model: {pruned_model_size:,} bytes')
出力結果
Size of the the Original Model: 498,298,726 bytes Size of the the Pruned Model: 390,194,063 bytes
Pruning前と比較しPruning後の圧縮後モデルサイズが小さくなっていることが確認できました。
評価結果まとめ
Pruningするパラメータの割合を変えてモデルの精度、サイズを確認し、下記の通り結果をまとめました。
| Pruning率 | 正解率 | モデルサイズ(圧縮後) |
|---|---|---|
| 0% (オリジナルモデル) | 61.0% | 498MB |
| 30% | 60.6% | 390MB |
| 50% | 60.1% | 301MB |
| 70% | 55.6% | 207MB |
| 90% | 10.2% | 100MB |
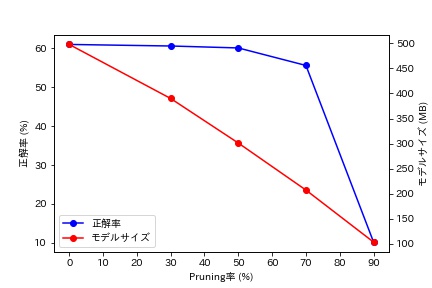
さすがに70%を超えるパラメータをPruningすると大きく精度が低下しますが、Pruning率50%程度なら正解率の低下を1%未満に抑えつつモデルを圧縮することができています。
おわりに
以上、モデル圧縮手法 Pruning を PyTorch で試してみました。簡単なコードで精度の低下を抑えつつモデルを圧縮することができることを確認していただけたかと思います。
しかし今回試した非構造的Pruningはネットワークの構造を変えないため、基本的に計算速度は改善されません。
計算速度を改善したい場合は一般的に非構造的Pruningと比較して精度低下が大きいとされますが、ニューロンを除外しネットワークの構造自体を変化させる構造的Pruningを試してみるのもよいかもしれません。
モデル圧縮は軽量化・高速化につながる重要な手法なので今後も随時調査していきたいと思います。
オプティムではモデルのたるんだボディを積極的にシェイプアップするエンジニアを募集しています。