まえがき
プレイ時間200時間にして念願の初ソロドン勝を達成しもう思い残すことはないR&Dチームの宮﨑です。
ちょうど一か月ほど前の11/13にPyTorch Mobileが(プロトタイプですが)Android NNAPIをサポートというアナウンスがありました。公式によると10倍高速化されたケースもあるとのことで、さっそくチュートリアルのベンチマークを走らせてみました!
OPTiM TECH BLOG Advent Calendar 2020 12/14の記事です。
PyTorch Mobileとは
対応する演算子の豊富さや書きやすさなどから人気を誇るPyTorchですが、ここ最近はPyTorchモデルをC++/Mobile対応のモデルに変換してくれるTorchScriptなどプロダクションへの取り組みも活発になってきました。そのMobile対応したモデルを動作させる機構がPyTorch Mobileです。もちろんiOS/Androidに対応しています。本記事執筆時点ではまだβ版のようですね。*1
NNAPIとは
NNAPIを用いることで自動的に選択されたハードウェア(GPUなど)による機械学習の推論を行うことができます。TensorFlow Liteなど他の深層学習フレームワークでは以前から対応しているものもありましたがとうとうPyTorch Mobileでもプロトタイプですが対応しました。
PyTorch MobileをNNAPIに対応させる手順
従来PyTorch Mobileで用いてきたモデル(TorchScriptモデル)に対して専用の関数で変換をかけてあげます。NNAPI対応のモデルが生成されるので従来使っていたモデルとすり替えます。これだけです!
生成されたNNAPI対応のモデルも何ら変哲のないTorchScriptモデルなので従来のPyTorch Mobileのモデルと同様に扱えます。
NNAPIの性能計測までの流れ
主に公式のNNAPIのチュートリアルに従っています。PyTorch Mobileのパフォーマンス計測チュートリアルにもある通り、ベンチマークは実際のユースケースに適用したものを計測するのがベストですが、PyTorch公式が用意したPyTorch Mobile用のスクリプトを用いて生成したモデルの推論速度を手軽に計測できるバイナリをビルドすることができます。スクリプトの具体的な内容としてはLibTorch上で指定された形式で生成されたダミーINPUTを指定されたモデルでforwardしたものを計測しているようです。
- 計測するモデルを入手
pip install --upgrade --pre --find-links https://download.pytorch.org/whl/nightly/cpu/torch_nightly.html torch==1.8.0.dev20201106+cpu torchvision==0.9.0.dev20201107+cpuを叩いてNNAPI対応のPyTorch環境を整えます。筆者はWSL上のAnacondaで構築しました- チュートリアルにあるモデル生成用のPythonスクリプトを走らせる
mobilenetv2-quant_core-cpu.ptmobilenetv2-quant_core-nnapi.ptmobilenetv2-quant_full-cpu.ptmobilenetv2-quant_full-nnapi.ptmobilenetv2-quant_none-cpu.ptmobilenetv2-quant_none-nnapi.ptの6つのモデルが手に入る
- 計測スクリプトのバイナリを入手
- PyTorchリポジトリのscriptsへ移動し、Android - Benchmarking Setupにしたがって計測スクリプトをビルドする
- 今回使用する計測スクリプトのバイナリ
speed_benchmark_torchを手に入れる
- NNAPIに対応したAndroid*2に転送する
- 計測するモデルと計測スクリプトのバイナリを
adb push <転送するもの> <転送先パス>でAndroidに転送する。転送先は/data/local/tmpにするとpermissionで躓かないのでお手軽です - 計測スクリプトを起動して計測。オプションはチュートリアルに例として挙げられている
./speed_benchmark_torch --pthreadpool_size=1 --model=mobilenetv2-quant_full-nnapi.pt --use_bundled_input=0 --warmup=5 --iter=200や元コードを参考にすると良いでしょう
- 計測するモデルと計測スクリプトのバイナリを
ベンチマーク結果
- Pixel4で計測しました
- 計測コマンドは次の形式です。
./speed_benchmark_torch --pthreadpool_size=1 --model=<model> --use_bundled_input=0 --warmup=5 --iter=200 - 各モデルの
none、core、fullは以下を表します。- none: 量子化なしの浮動小数点のモデル
- core: モデルのコアは量子化してあるがインターフェースは浮動小数点のモデル
- full: 全て量子化したモデル
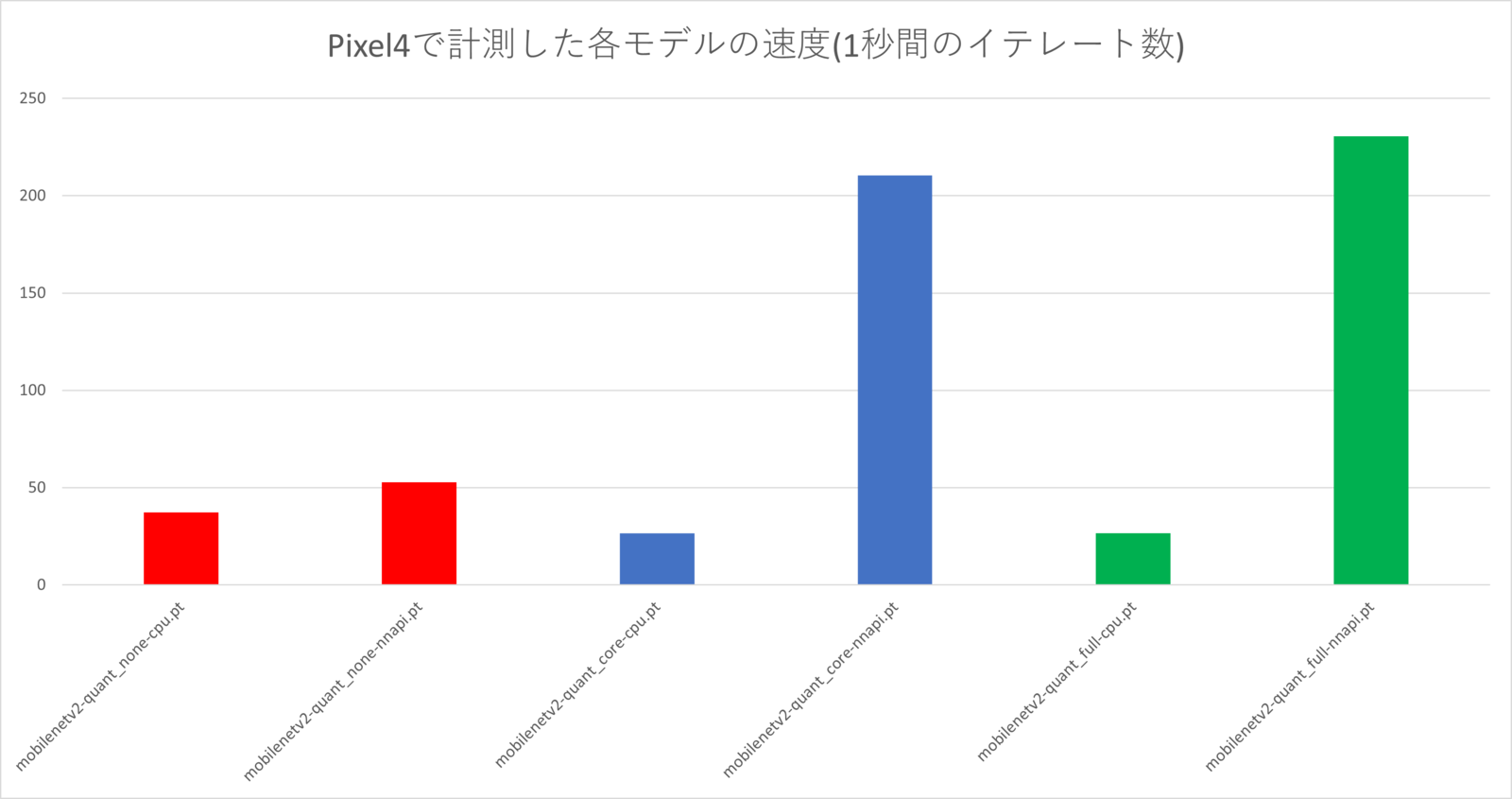
- NNAPIにすることでnoneでは1.42倍、coreでは7.94倍、fullでは8.65倍の速度になっておりかなり高速化されていることが分かります
最後に
今回はPyTorch MobileのNNAPIについて周辺知識とベンチマークの様子をご紹介しました。後にMask R-CNNもサポートする予定とのことで楽しみですね。密かに成長するPyTorchの汎用性に目を向ける人が増えてくれると嬉しいです。
オプティムはお昼寝が好きなエンジニアを募集しています。