はじめまして、OPTiMの久末です。私は現在R&Dチームに所属している新卒1年目のスタッフで、普段は様々な物体の行動を映像から解析する日々を過ごしています。
今回はそんな私が、普段使っている技術に関して、そのバックボーンとなる部分も含めてお話しさせていただければとおもいます。
なお、今回のブログの内容は以前のブログで和田から紹介させていただいた「OPTiM TECH Seminar」で私がお話しさせていただいた内容を元に再構成しています。
そもそもなぜニューラルネットワークが流行ったのか
現在、巷では「AI」という言葉がかなりの流行を見せているかと思います。実際には差異があるのでしょうが、現在広く使われている「AI」という言葉は、ニューラルネットワークを用いた機械学習、その中でも特に深層学習をさしている場合が多いように感じています。ではなぜ、深層学習と呼ばれる手法がここまでの流行を見せているのか、そのあたりを簡単にお話しさせていただきます。
ILSVRC
最も大きなきっかけは、ILSVRC (ImageNet Large Scale Recognition Challenge) だと言われています。これは後ほど紹介させていただく、ImageNetと呼ばれる大規模なデータセットを用いて様々な分野の画像認識の精度を競うコンペティションです。2010年から毎年行われており、2012年のこのコンペティションの画像分類の分野で深層学習を用いた手法の一つである、AlexNetがそれまでの記録を大きく塗り替えました。この結果を受け、その後深層学習による手法が急速に普及し、現在でも広く使われているVGGやResNetと行った有名な手法が考案されました。この辺りも後ほど紹介させていただきます。

ILSVRC Top-5 error
ImageNet
先ほど名前だけ登場しましたが、深層学習の発展には膨大なデータ量をもつImageNetの存在も大きく寄与しています。ImageNetは現在、1400万枚を超える画像とその画像に何が写っているかと行った情報が収録されているパグリックなデータセットです。物体のクラス数は現在20000クラスを超えています。先ほど紹介させていただいた ILSVRC の2012年のコンペティションではこの中から1,000クラス、約140万枚の画像が抽出され利用されました。
深層学習において、データセットの存在はとても大きなものです。少ないデータセットを水増しして学習するような学習方法も多々考案されていますが、現状はそのような手法よりも人間が作成した質の高いデータセットを数多く揃える方が明らかに精度が向上することが一般に知られています。
また、数の少ないデータセットを深い構造や複雑な構造をもつCNNで学習させると過学習が起こりやすくなり精度がでなくなる場合が多いです。ImageNetのような膨大な数をもつデータセットを学習させ、それを事前学習モデルとして学習させることで様々な手法が試しやすくなり、深層学習の手法が発展しやすくなります。
有名な深層学習手法
ここではILSVRCで登場した有名な深層学習手法を紹介したいと思います。
VGG
2014年のILSVRCに登場しました。畳み込み層とプーリング層を繰り返す、基本的なCNNの構造をしています。16層や19層程度のある程度の深い構造を持ち、数回畳み込みを行った後プーリングを行うと行った操作を繰り返します。
GoogleNet
2014年の ILSVRC に登場しました。当時の精度はVGGよりも高く、2014年のILSVRCではこの手法が優勝、VGGが準優勝という結果になっています。
GoogleNet の最大の特徴は深さだけではなく幅を広げたインセプションと呼ばれる構造です。インセプション構造は複数の異なるフィルタを適用しそれらを合算するような構造です。
下記画像をみていただけるとイメージが湧きやすいと思いますが、VGG に比べて複雑な構造をしており、また劇的に精度が変化した訳ではなかったので、GoogleNetよりもVGGを元に発展させる研究がのちに盛んに行われるようになりました。
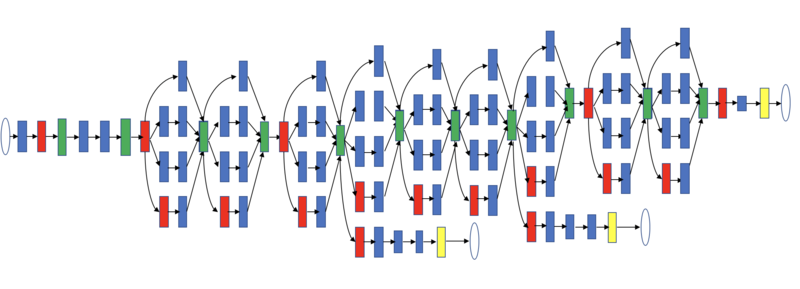
GoogleNet の構造
(https://arxiv.org/abs/1409.4842 を参考に作成)
ResNet
2015年のILSVRCに登場しました。構造はVGGを発展させたものです。
ResNetの最大の特徴は層をより深くするために考案されたスキップ構造です。これによって勾配消失を抑える効果があり、層を一気に深くすることが可能になりました。ILSVRC時には152層という非常に深いネットワーク構造のものが利用されています。
2015年の画像分類のTop-5のエラー率(画像の中に写っている物体の候補を五つあげてその中に正解が入っていない確率)が3.5%しかなく、これは人間の認識精度を超えたとも言われています。
このResNetのさらに発展形が後ほど登場します。
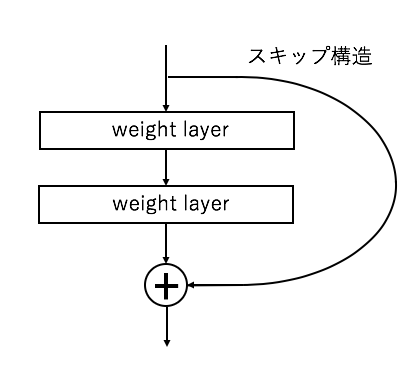
ResNetのスキップ構造
(https://arxiv.org/abs/1512.03385 を参考に作成)
機械学習による行動認識の歴史
ここからは、現在私がOPTiMで取り組んでいる行動認識のお話をさせてもらおうと思います。
行動認識とは
カメラやセンサなどが取得した情報を元に対象がどのような行動を行なっているのかを解析する認識技術のテーマのひとつです。
多くの場合、人間を対象としていることが多いですが、その他のものも対象となり得ます。
今回はカメラ映像を元とする形について主にお話しします。
従来の手法
行動認識にも様々な手法が提案されています。TOFカメラやキネクトに代表される深度カメラの登場によって、通常の可視光カメラに比べて映像からの行動認識がかなり行いやすくなりました。またオプティカルフローのような手法も考案されました。従来はこれらの情報を様々な手法により分類することによって行動認識を行う取り組みが行われていました。
当然、その分類にCNNを用いる手法も提案されました。先述の通り、現在、画像分類においてCNNは他の追随を許さない精度を記録しています。オプティカルフロー画像や深度カメラの画像を入力として、CNNによる分類によって行動を分析する取り組みです。これによって確かに精度の向上が確認できました。
また、CNN + LSTM のような時系列データを持たせようとした取り組みもあります。動画内の行動というのは物体検出などとは違い、その時その時で完結するものではないため、時系列データを用いるのも良い手法であると思います。
3D-CNN
これまで簡単に紹介してきた手法でCNNを用いているものは基本的に、二次元の畳み込みしか行わない2D-CNNです。この手法は https://www.adaptilab.com/blog/squeezenet-model などで紹介されているようなアニメーションを確認していただけるとわかりやすいと思いますが、全てのチャネル方向の情報は同時に処理されてしまい、有効活用しきれていると言いづらいものでした。例えば物体検出を行いたい場合、チャネル軸方向にはRGB情報を入力とすることが多いです。この情報を強く残してしまうと、物体の色に依存して検出が行えたり行えなかったりといったことが起こりやすくなる可能性があるため、これらの情報を強く利用しないことは問題となりませんでした。しかし、行動認識を行いたい場合、多くの手法はチャネル方向に時間軸の情報を持ちます。これが同時に処理されてしまい、出力されるときには合算されてしまっているのはあまり良くありません。この課題を解決するために様々な手法が考案されました。そのうちの一つが 3D-CNN です。3D-CNNではチャネル方向も局所的な畳み込みを行うため、時間軸による変化の特徴量も抽出しやすいことが予想されます。これを利用した行動認識モデルとしてC3Dやその発展系のI3Dなどが有名です。
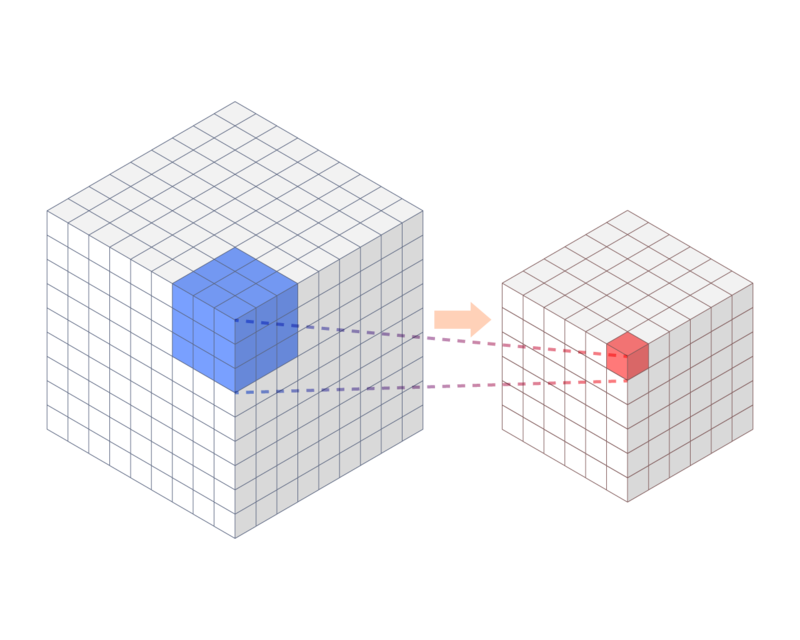
3次元の畳み込み
(http://db-event.jpn.org/deim2018/data/papers/3.pdf を参考に作成)
行動分類データセット
行動認識の分野においてもパブリックなデータセットは数多く存在しています。ここではそのうちのいくつかを紹介します。
| 名前 | クラス数 | インスタンス数 |
|---|---|---|
| HMDB-51 | 51 | 6,849 |
| UFC-101 | 101 | 13,320 |
| ActivityNet (v1.3) | 200 | 23,064 |
| Kinetics | 400 | 300,000以上 |
また、より大きなデータセットとして、Sports-1MやYoutube-8Mなどが知られていますが、これらには余計なフレームが含まれている場合が多く、アノテーションの精度があまり良いとは言えません。
3D-CNNの発展
冒頭でお話しした通り、2D-CNNでは層を深くするほど精度が向上する場合が多かったため、3D-CNNにおいても同様に層を深くする取り組みが行われてきました。しかし、HMDB-51、UFC-101、ActivityNetのようなデータセットでは深い層を試すためのデータセットとしてサイズが小さすぎました。これは、これらのデータセットを用いて深いアーキテクチャをもつモデルを学習させると、簡単に過学習を起こしてしまうためです。これを解消するために様々なデータセットが用意されましたが、その中でも2017年に登場した Kinetics が一際注目を集めています。これは、400クラスそれぞれを最低400インスタンス以上集めたもので、総インスタンスは300,000を超えます。このデータセットを用いることで、ImageNetと同レベルの層の深さまでであれば、オーバーフィッティングすることなく拡張可能であることが実験的に証明されました。1
これによって、3D-CNNも2D-CNNと同様に深い層をもつモデルの作成が可能となったことになります。
3D-ResNets
有名な深層学習手法のセクションで紹介した、ResNetをそのまま3Dに拡張した3D-ResNetが2017年に発表されました。2
これは日本人が開発しており、論文がかなり読みやすく、またソースコードも同時に公開3されているためかなり利用しやすくなっています。ResNetの発展形である WideResNet、Pre-activation ResNet、ResNeXt、DenseNetにも対応しており、ResNet、ResNeXt、DenseNetについてはKineticsデータセットによる事前学習モデルも公開されています。ここではKineticsデータセットで事前学習させ、転移学習を行なった結果を論文から引用させていただきます。
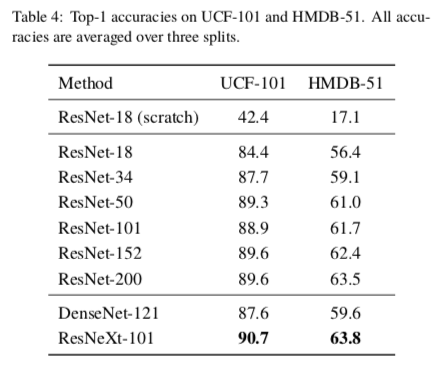

3D-ResNetsの精度
(出典 : https://arxiv.org/abs/1708.07632 )
上図から3D-ResNetsの層を深くすればするほど、基本的には精度が向上している様子が確認できます。200層が効果が薄いのはImageNetと2D-ResNetの組み合わせの場合も同様です。また、論文内でも言及されていますが、DenseNet構造は3D-CNNにおいてはあまり効果が無いようです。
ResNeXt-101 (64f) はResNeXt-101 よりも画像の入力サイズを大きくしたものです(元々のサイズが小さすぎたので他の手法に合わせる形です)。わずかではありますが従来のstate-of-the-art手法よりも全般的に精度が上がっている様子が確認できると思います。
また、Two-stream I3Dではより高い精度が出ているため、RGB画像だけでなくオプティカルフロー画像も同時に入力として用いるTwo-stream手法に対応すればさらに精度の改善が見込めます。
全体的な流れ

さいごに
OPTiMでは行動認識にも力を入れています。
行動認識に関するほとんどの論文では人間の行動の解析を主としていますが、OPTiMでは人間だけに限らず、動物や非生物の行動の分析も行なっています。それらの解析には3D-ResNetsを用いる場合が多いです。もちろん、そのまま利用できることはほとんどなく様々な工夫が必要ではあります。
例えば、行動認識モデルは動画の画面内に対象の物体が大きく写っているケースでは精度を出しやすいですが、画面の一部に対象の物体が写っているものの余計なものもたくさん写り混んでいるといったケースではうまく解析できないことが多いです。これは実際の案件に組み込むため際にかなり大きな問題になります。行動認識が活躍する場面の多くは対象を長時間監視したいようなシーンです。しかし、監視対象がカメラの目の前から離れないことが保証されていなければ使えないのであればかなり用途が限定されてしまいます。そのような場合、OPTiMでは既存の物体検出技術や物体追跡技術を併用し、自動で動画をクロップして行動を解析するといったパイプラインをとっています。これによって多少カメラから離れていても余計な情報を排除することができ、高精度な解析が可能になります。
最近ではそういったさまざまな知見もかなり集まってきており、実際の案件に組み込めるケースも増えてきました。
行動認識に興味があるという方は是非一度オプティムを訪れてみてください。